ĪĪĪĪ┤¾öĄō■▓╗āH╩Ū╚╦éā½@Ą├ą┬šJų¬Īóäōįņą┬ārųĄĄ─į┤╚¬Ż¼▀Ć╩ŪĖ─ūā╩ął÷ĪóĮM┐ŚÖCśŗŻ¼ęį╝░š■Ė«┼c╣½├±ĻPŽĄĄ─ĘĮĘ©ĪŻ[1]╩«░╦ī├╬Õųą╚½Ģ■ĪČųą╣▓ųąčļĻPė┌ųŲČ©ć°├±ĮøØ·║═╔ńĢ■░lš╣Ą┌╩«╚²éĆ╬Õ─ĻęÄäØĄ─Į©ūhĪĘÅŖš{Ż¼┤┘▀M╗ź┬ōŠW║═ĮøØ·╔ńĢ■╚┌║Ž░lš╣Ż¼īŹ╩®ć°╝ę┤¾öĄō■æ┬įŻ¼═Ų▀MöĄō■┘Yį┤ķ_Ę┼╣▓ŽĒĪŻļSų°ć°╝ę┤¾öĄō■æ┬įĄ─īŹ╩®Ż¼┤¾öĄō■ī”Öz▓ņ└Ēšō蹊┐╝░Öz▓ņīŹ█`ę▓«a╔·┴╦ØōęŲ─¼╗»Ą─ė░Ēæ[2]ĪŻęįą┬╦╝ŠSĪóą┬╝╝ągæ¬ī”║Ż┴┐öĄō■Ą─ø_ō¶Ż¼╣▄└ĒĪóķ_░l║═æ¬ė├║├Öz▓ņ╬─½IŻ¼▓┼─▄Ė³║├Ąž×ķÖz▓ņ└Ēšō蹊┐║═Öz▓ņīŹ█`╠ß╣®ėą┴”╬─½Ių¦ō╬ĪŻ
ĪĪĪĪę╗ĪóöĄūų╗»Öz▓ņ╬─½IĄ─┤¾öĄō■ī┘ąį
ĪĪĪĪŻ©ę╗Ż® ┤¾öĄō■Ą─ų„ę¬╠žš„
ĪĪĪĪļSų°įŲėŗ╦ŃĄ╚╝╝ągĄ─┼dŲŻ¼ęį╝░╬ó▓®Īó╬óą┼Ą╚ą┬ą═ą┼Žó░l▓╝ĘĮ╩ĮĄ─▓╗öÓė┐¼FŻ¼öĄō■ęįŲõŪ░╦∙╬┤ėąĄ─╦┘Č╚▓╗öÓį÷ķLĪó└█ĘeŻ¼▓óĖ─ūāų°╚╦ŅÉĄ─╦╝ŠSĪó╔·«aĪó╔·╗Ņ║═īW┴ĢĄ─ĘĮ╩ĮĪŻ┤¾öĄō■┼cé„ĮyöĄō■Ą─ĻPŽĄ┐╔ęį▒╚ū„Ī░┤¾║ŻĪ▒ų«ė┌Ī░¶~╠┴Ī▒ĪŻ[3]─┐Ū░īWągĮńļm╚╗ī”┤¾öĄō■Ą─Č©┴x╝░╠žš„╔ą╬┤▀_│╔ę╗ų┬Ż¼Ą½╗∙ė┌▀@ę╗ŅÉ▒╚Ż¼┤¾öĄō■Ą─ų„ę¬╠žš„ų„ę¬ėąęÄ─ŻąįŻ©VolumeŻ®ĪóČÓśėąįŻ©VarietyŻ®ĪóĖ▀╦┘ąįŻ©VelocityŻ®╝░ārųĄąįŻ©ValueŻ®ĪŻ
ĪĪĪĪ1. ęÄ─ŻąįĪŻ┤¾öĄō■ų«╦∙ęįĘQų«×ķĪ░┤¾öĄō■Ī▒Ż¼ūŅų▒ĮėĄ─įŁę“Š═į┌ė┌öĄō■Ą─ęÄ─ŻąįĪŻęįėŗ╦ŃÖCĄ─CPU ║═öĄō■┤µā”╝╝ąg╦«ŲĮČ°čįŻ¼é„ĮyöĄō■ÄņĄ─╠Ä└Ēī”Ž¾═©│ŻęįMBĪóGB×ķ╗∙▒Šå╬╬╗Ż╗Č°┤¾öĄō■├µī”Ą─╗∙▒Š╠Ä└Ēå╬╬╗ę¬ęįTB Ż© 1024GBŻ® ╝░ęį╔ŽĄ─å╬╬╗üĒ▒Ē├„öĄō■┴┐ĪŻ
ĪĪĪĪ2. ČÓśėąįĪŻé„ĮyöĄō■Äņ╠Ä└Ēī”Ž¾Ą─öĄō■ŅÉą═▌^×ķå╬ę╗Ż¼āHėąę╗ĘN╗“╔┘öĄÄūĘNŻ¼Ūę═©│Ż×ķęį0║═1×ķ▒Ē¼Fą╬╩ĮĄ─Č■▀MųŲöĄō■Ż╗Č°┤¾öĄō■├µī”Ą─öĄō■ŅÉą═Ę▒ČÓŻ¼▓╗āH░³║¼é„ĮyĄ─öĄō■Ż¼▀Ć░³║¼üĒūįŠWĒōĪó╗ź┬ōŠW╚šųŠ╬─╝■Īó╦č╦„╦„ę²Īó╔ńĮ╗ŠWĮjĪóų„äė║═▒╗äėŽĄĮyĄ─é„ĖąŲ„öĄō■Ą╚ĮYśŗ╗»Īó░ļĮYśŗ╗»ęį╝░ĘŪĮYśŗ╗»öĄō■Ż¼Ūęęį║¾ā╔š▀ŠėČÓĪŻ
ĪĪĪĪ3. Ė▀╦┘ąįĪŻ┤¾öĄō■Ģr┤·öĄō■╠Ä└Ēę¬Ū¾Ė▀╦┘ąįŻ¼╝┤ę¬į┌║▄Č╠Ģrķgā╚Įo│÷Ęų╬÷ĮY╣¹Ż¼ęį▒ŃÅ─Ė„ĘNŅÉą═Ą─öĄō■ųą┐ņ╦┘½@Ą├Ė▀ārųĄĄ─ą┼ŽóĪŻ┤¾öĄō■Ą─Ė▀╦┘ąįę¬Ū¾┐ŲīW蹊┐Ą─╦╝┬Ę▒žĒÜÅ─ęįėŗ╦Ń×ķųąą─▐DūāĄĮęįöĄō■╠Ä└Ē×ķųąą─Ż¼ą╬│╔╦∙ų^Ą─öĄō■╦╝ŠSĪŻ[4]▀@ĘN蹊┐╦╝┬ĘĄ─ūā╗»▒žīóĦüĒ蹊┐ĘĮĘ©Ą─ūāĖ’ĪŻ
ĪĪĪĪ4. ārųĄąįĪŻārųĄąį¾w¼F┴╦┤¾öĄō■蹊┐Ą─šµīŹęŌ┴xĪŻ┤¾öĄō■Ą─蹊┐╣żū„īŹ┘|╩Ūīóą┼╠¢▐D╗»×ķöĄō■Ż¼īóöĄō■Ęų╬÷×ķą┼ŽóŻ¼īóą┼Žó╠ߤÆ×ķų¬ūRŻ¼ęįų¬ūR┤┘│╔øQ▓▀║═ąąäėĄ─▀^│╠ĪŻĄ½╩Ūį┌║Ż┴┐Ą─öĄō■├µŪ░Ż¼ārųĄŠ▀ėąŽĪ╚▒ąįĪ¬Ī¬öĄō■ęÄ─ŻįĮ┤¾Ż¼šµš²ėąārųĄĄ─öĄō■┼cöĄō■ęÄ─ŻŽÓ▒╚Č°čįģs▌^╔┘Ż¼ęįé╔ŲŲ░Ė╝■ųąęĢŅl┼·┴┐öĄō■×ķ└²Ż¼į┌▀B└m▓╗öÓĄ─▒O┐ž▀^│╠ųąŻ¼┐╔─▄ėąė├Ą─öĄō■āHāHėąę╗ā╔ĘųńŖĪŻ
ĪĪĪĪŻ©Č■Ż®öĄūų╗»Öz▓ņ╬─½IĄ─ā╚║Ł┼cĘųŅÉ
ĪĪĪĪć°╝ęś╦£╩ĪČ╬─½Ių°õø┐éätĪĘųąīóĪ░╬─½IĪ▒Č©┴x×ķĪ░ėøõøėąų¬ūRĄ─ę╗Ūą▌d¾wĪŻĪ▒ Öz▓ņ╬─½Iī┘ė┌╬─½IĄ─ę╗ĘNŻ¼ųĖėøõøÖz▓ņų¬ūR║═ą┼ŽóĄ─ę╗Ūą▌d¾wĪŻöĄūų╗»Öz▓ņ╬─½Iät╩ŪęįöĄūųą╬╩Į┤µā”Ą─Öz▓ņ╬─½IŻ¼ŠWĮjė├æ¶ĮĶų·╗ź┬ōŠWŻ¼┐╔ęį▓╗╩▄Ģrķg║═ł÷╦∙Ą─Ž▐ųŲŻ¼į┌║▄Č╠Ģrķgā╚üĒÖz╦„║═╩╣ė├╦³éāŻ¼┤¾┤¾╠ßĖ▀┴╦╣żū„ą¦┬╩ĪŻ
ĪĪĪĪĖ∙ō■╬─½Iā╚╚▌Īóąį┘|║═╝ė╣żŪķør┐╔īó╬─½IĘų×ķŻ║┴Ń┤╬╬─½IĪóę╗┤╬╬─½IĪóČ■┤╬╬─½IĪó╚²┤╬╬─½IĪŻŲõųąŻ¼┴Ń┤╬╬─½I╩ŪųĖėøõøį┌ĘŪš²ęÄ╬’└Ē▌d¾w╔ŽĄ─╬┤Įø╚╬║╬╝ė╣ż╠Ä└ĒĄ─į┤ą┼ŽóŻ╗ę╗┤╬╬─½IųĖęįū„š▀▒Š╚╦Ą─蹊┐│╔╣¹×ķę└ō■Č°äōū„Ą─╬─½IŻ¼╚ńŲ┌┐»šō╬─Īó蹊┐ł¾ĖµĪóīŻ└¹šf├„Ģ°ĪóĢ■ūhšō╬─Ą╚Ż╗Č■┤╬╬─½I╩Ūī”ę╗┤╬╬─½I▀Mąą╝ė╣żš¹└Ē║¾Ą─«a╬’Ż¼╚ń─┐õøĪó╬─š¬Ą╚Ż╗╚²┤╬╬─½I╩ŪųĖī”ėąĻPĄ─ę╗┤╬╬─½IĪóČ■┤╬╬─½I▀MąąÅVĘ║╔Ņ╚ļĄ─Ęų╬÷蹊┐ų«║¾ŠC║ŽĖ┼└©Č°│╔Ą─«a╬’Ż¼░³└©ŠC╩÷ĪóīŻŅ}╩÷įuĪóīW┐Ų─ĻČ╚┐éĮYęį╝░╬─½IųĖ─ŽĄ╚ĪŻ
ĪĪĪĪĖ∙ō■╬─½IĄ─ĘųŅÉ┐╔ęįīóöĄūų╗»Öz▓ņ╬─½IĘų×ķ┴Ń┤╬Öz▓ņ╬─½IĪóę╗┤╬Öz▓ņ╬─½IĪóČ■┤╬Öz▓ņ╬─½I║═╚²┤╬Öz▓ņ╬─½IŻ©ęįŽ┬īóę╗┤╬ĪóČ■┤╬Īó╚²┤╬Öz▓ņ╬─½IĮyĘQ×ķĘŪ┴Ń┤╬Öz▓ņ╬─½IŻ®ĪŻ
ĪĪĪĪ─┐Ū░Ż¼īŻśI╗»│╠Č╚▌^Ė▀Ą─╔╠śIąį╬─½IöĄō■╔╠ęčīóėąą®Öz▓ņŅÉłDĢ°Īó┤¾ČÓöĄÖz▓ņŲ┌┐»║═Öz▓ņ┤T▓®╩┐šō╬─Ą╚ĘŪ┴Ń┤╬Öz▓ņ╬─½I▀Mąą┴╦öĄūų╗»Ż¼ė├æ¶┐╔ęį┘Å┘I╩╣ė├ĪŻ┼cų«ŽÓ▒╚Ż¼┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─ķ_░l┼c└¹ė├ät▌^▒Ī╚§ĪŻĄ½╩ŪĘŪ┴Ń┤╬╬─½Ię╗ų▒╩▄ĄĮīWągĮńĄ─śO┤¾ĻPūóŻ¼ų╗╩Ūė╔ė┌┴Ń┤╬╬─½IöĄ┴┐²ŗ┤¾Īóą╬╩ĮžSĖ╗ĪóĘų▓╝┴ŃąŪŻ¼Ūę╠Äį┌╬┤Įø╝ė╣żĄ─įŁ╩╝Ą─¤oą“ĀŅæBŻ¼═∙═∙Ą├▓╗ĄĮ╚╦╣ż╬’╗»[5]ĪŻ╚╗Č°Ż¼ļSų°╗ź┬ōŠWĄ─Ųš╝░║═░lš╣Ż¼įĮüĒįĮČÓĄ─īŻ╝ęīWš▀ęŌūRĄĮ┴Ń┤╬╬─½IĄ─ųžę¬ąįĪŻĖ∙ō■ĪČ┐ŲīWę²╬─╦„ę²ĪĘŻ©SCIŻ®Ą─šō╩÷║═ėąĻPŪķł¾ÖCśŗĄ─įu╣└┘Y┴Ž’@╩ŠŻ¼┴Ń┤╬╬─½Iį┌š¹éĆą┼Žóį┤ųą╦∙š╝Ą─▒╚└²ęčĮø│¼▀^20%Ż¼Č°Ūę▀Ć╠Äė┌╔Ž╔²æBä▌[6]ĪŻį┌┤¾öĄō■▒│Š░Ž┬Ż¼ŠWĮjé„▓źųąŠ▀ėąÖz▓ņų¬ūRĄ─┤¾┴┐įŁ╔·æB╬─½IŠ∙┐╔ęĢ×ķ┴Ń┤╬Öz▓ņ╬─½IŻ¼╚ń╬ó▓®Īó╬óą┼Ą╚╔ńĮ╗├Į¾w×ķ╚╦éā▒Ē▀_ęŌųŠ║═ęŌęŖ╠ß╣®┴╦ŲĮ┼_Ż¼╩Ū╔ńĢ■▌øšōĄ─ų„ę¬▌d¾wŻ¼─▄ē“Ę┤ė│╚╦éāī”Öz▓ņ╣żū„Ą─æBČ╚Ż¼Č╝┐╔│╔×ķ┴Ń┤╬Öz▓ņ╬─½IĄ─ųžę¬üĒį┤ĪŻĄ½╩ŪŻ¼ŠWĮjųąļSęŌĻPė┌Öz▓ņĄ─ų╗čįŲ¼šZŻ¼▓╗ī┘ė┌┴Ń┤╬Öz▓ņ╬─½IŻ¼ę▓▓╗╩ŪŪ░╬─½Ią╬æBŻ¼ę“×ķ▀@ą®ą┼Žó▓╗║¼Øōį┌ārųĄŻ¼¤oĘ©│╔×ķÖz▓ņ╬─½IĪŻ
ĪĪĪĪŻ©╚²Ż®öĄūų╗»Öz▓ņ╬─½I┼c┤¾öĄō■Ą─ĻPŽĄ
ĪĪĪĪļSų°įŲėŗ╦ŃĄ╚ėŗ╦ŃÖC╝╝ąg║══©ą┼╝╝ągĄ─░lš╣Ż¼į┌╬ęć°╚½├µ╔Ņ╗»╦ŠĘ©¾wųŲĖ─Ė’Ą─¼FīŹ▒│Š░Ž┬Ż¼ęįöĄūųą╬╩Įėø▌d║═é„│ąÖz▓ņų¬ūR║═╬─╗»Ą─Öz▓ņ╬─½IĄ─öĄ┴┐į┌▓╗öÓį÷╝ėĪŻ
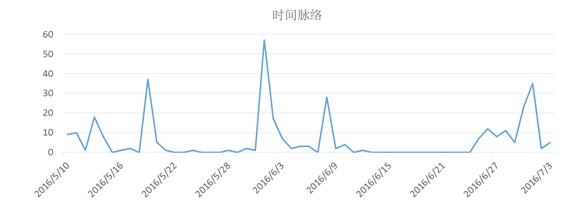
ĪĪĪĪŠ═ĘŪ┴Ń┤╬Öz▓ņ╬─½IüĒšfŻ¼łD1š╣╩Š┴╦1980-2015─Ļųąć°ų¬ŠW╩šõøĄ─╬─½IųąŲ¬├¹ųą║¼ėąĪ░Öz▓ņĪ▒Ą─╬─½IöĄ┴┐Ż¼┐╔ęį┐┤│÷ĘŪ┴Ń┤╬Öz▓ņ╬─½IöĄ┴┐į÷ķL┐╔ęįĘų×ķ╦─éĆļAČ╬Ż¼╝┤ŠÅ┬²į÷ķLĄ─│§╩╝ļAČ╬ĪóųĖöĄį÷ķLļAČ╬ĪóŠĆąįį÷ķLļAČ╬║═ŠÅ┬²į÷ķLļAČ╬ĪŻ
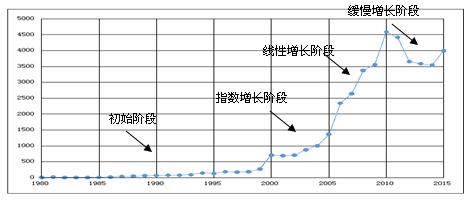
ĪĪĪĪłD1 1980-2015─Ļųąć°ų¬ŠW╩šõøĄ─Ų¬├¹║¼ėąĪ░Öz▓ņĪ▒Ą─╬─½IöĄ┴┐
ĪĪĪĪ╚╗Č°Ż¼┼cĘŪ┴Ń┤╬Öz▓ņ╬─½Iį÷ķLŪķør▓╗═¼Ż¼┴Ń┤╬Öz▓ņ╬─½IĄ─į÷ķLŻ¼ė╚Ųõ╩Ūį┌┤¾öĄō■▒│Š░Ž┬Ż¼ļSų°Ī░╚╦╚╦Č╝╩Ūūį├Į¾wĪ▒╠žš„Ą─▓╗öÓ’@¼FŻ¼ŲõöĄ┴┐Ą─į÷ķL│╩¼FĪ░Š«ćŖæBä▌Ī▒ĪŻ└²╚ńŻ¼═©▀^░┘Č╚╦č╦„ę²ŪµęįĪ░Öz▓ņĪ▒ū„×ķĻPµIį~Ż¼Įžų╣2016─Ļ6į┬28╚šŻ¼ūŅĮ³ę╗─ĻĪóūŅĮ³ę╗į┬ĪóūŅĮ³ę╗ų▄ŲĮŠ∙├┐╠ņ░l▓╝ą┼ŽóöĄ┴┐Ęųäe×ķ22.99Īó186.67Īó350.00╚fŚlĪŻįōĮY╣¹ę╗ĘĮ├µ▒Ē├„┼cÖz▓ņŽÓĻPĄ─┴Ń┤╬╬─½IöĄ┴┐▀hĖ▀ė┌ĘŪ┴Ń┤╬╬─½IöĄ┴┐Ż╗┴Ēę╗ĘĮ├µę▓¾w¼F│÷┼cÖz▓ņŽÓĻPĄ─┴Ń┤╬╬─½IöĄ┴┐į÷ķL╦┘Č╚▀hĖ▀ė┌ĘŪ┴Ń┤╬╬─½IĪŻ’@╚╗Ż¼┴Ń┤╬Öz▓ņ╬─½IŠ▀éõ┤¾öĄō■╠žš„ųąĄ─ęÄ─ŻąįĪŻ┴Ē═ŌŻ¼ŠWĮj╔Ž┴Ń┤╬Öz▓ņ╬─½IĄ─ą┼Žóą╬╩Į░³└©╬─ūųĪółDŲ¼ĪóęĢŅlĪóę¶ŅlĄ╚Ą╚Ż¼ŪęĖ±╩Įę▓Ė„ėą▓╗═¼Ż╗▓óŪęŽÓ═¼ą┼Žóį┌▓╗═¼ŠWšŠųžÅ═│÷¼FŻ¼Å─Č°ī¦ų┬ėąārųĄĄ─ą┼Žó▒╗č═ø]į┌┤¾┴┐Ą─ųžÅ═ą┼Žóų«ųąĪŻė╔┤╦┐╔ęį┐┤│÷Ż¼┴Ń┤╬Öz▓ņ╬─½I═¼ĢrŠ▀éõ┤¾öĄō■Ą─ČÓśėąį║═ārųĄąį╠žš„ĪŻ
ĪĪĪĪį┌┤¾öĄō■▒│Š░Ž┬Ż¼ŠC║ŽöĄūų╗»Öz▓ņ╬─½Iķ_░l┼c└¹ė├Ą─¼FĀŅĪóąĶŪ¾╝░╬┤üĒ░lš╣┌ģä▌Ż¼öĄūų╗»Öz▓ņ╬─½IārųĄ╠ß╔²ę¬═©▀^ī”┴Ń┤╬║═ĘŪ┴Ń┤╬Öz▓ņ╬─½IĘųäe▀Mąą▌^×ķ╔Ņ╚ļĄ─öĄō■═┌Š“Ż¼īŹ¼F╬─½I┘Yį┤Ą─Č■┤╬ķ_░lŻ╗ūŅĮK─┐ś╦╩ŪöĄūų╗»Öz▓ņ╬─½IĄ─Įyę╗ķ_░l┼c└¹ė├Ż¼▓╗āH─▄īŹ¼F┴Ń┤╬╝░ĘŪ┴Ń┤╬Öz▓ņ╬─½Ią┼ŽóĄūīėöĄō■▓╔╝»Īó┤µā”Ą─Įyę╗╣▄└ĒŻ¼▀Ć─▄īŹ¼F┴Ń┤╬╝░ĘŪ┴Ń┤╬Öz▓ņ╬─½IöĄō■ą┼ŽóĄ─Į╗▓µ╣▓ŽĒŻ¼Å─Č°×ķ蹊┐š▀╠ß╣®╚½ĘĮ╬╗Īóę╗šŠ╩ĮÖz▓ņ╬─½IŠC║ŽĘ■äšĪŻŽ┬╬─īóĘųäeĻU╩÷ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½I║═┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─ķ_░l┼c└¹ė├Ż¼ęį╝░Č■š▀Ą─Įyę╗ķ_░l┼c└¹ė├ĪŻ
ĪĪĪĪČ■Īó┤¾öĄō■▒│Š░Ž┬ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─ķ_░l┼c└¹ė├
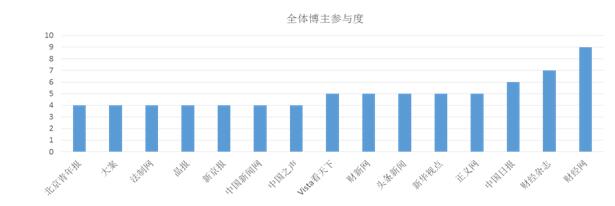
ĪĪĪĪ×ķīŹ¼FÅ─║åå╬Öz▓ņ╬─½Iį÷ųĄĘ■䚥ĮÖz▓ņ╬─½I╔ŅīėārųĄ╠ß╔²Ą─▐DūāŻ¼īóÖz▓ņ╬─½I╝ė╣ż╔·«a│╔ų¬ūR┘Yį┤Ż¼ę└ō■ė├æ¶ąĶŪ¾║═Ę■äšł÷Š░į┘ĮM┐ŚŻ¼╚╗║¾╠ß╣®Įoė├æ¶Ż¼┤┘▀Mė├æ¶ī”Öz▓ņų¬ūRĄ─└ĒĮŌ║═äōą┬Ż¼▒Š╬─ģó┐╝ųąć°ų¬ŠWĪó╚fĘĮöĄō■ĪóŠSŲšŲ┌┐»Ą╚ć°ā╚ų¬├¹īWągŠWšŠĄ─ŽÓĻP蹊┐│╔╣¹Ż¼╠ß│÷┴╦ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄŻ¼╚ńłD2╦∙╩ŠĪŻ
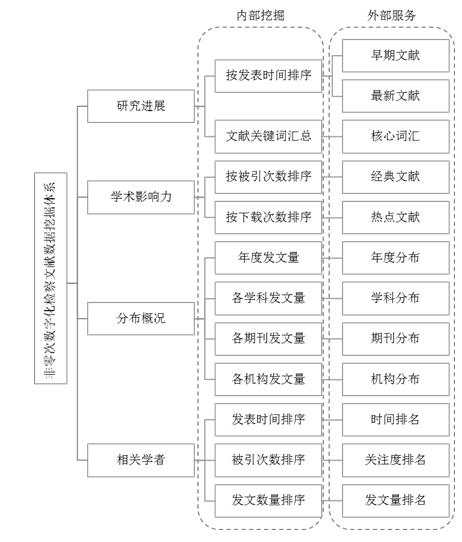
ĪĪĪĪłD2 ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄ
ĪĪĪĪŻ©ę╗Ż®čąŠ┐▀Mš╣
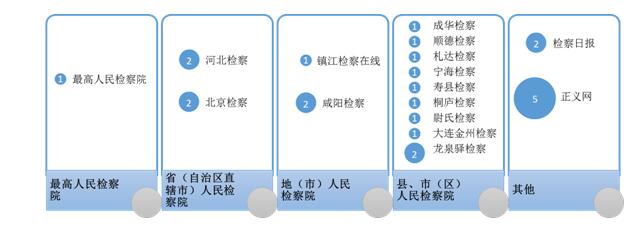
ĪĪĪĪ蹊┐▀Mš╣╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIį~Ż¼Å─ā╔éĆĘĮ├µ▀MąąĘų╬÷Ż║ę╗╩Ū░┤šš░l▒ĒĢrķg▀Mąą┼┼ą“Ż¼ęį▒Ńė├æ¶▓ķšęūŅįń╝░ūŅą┬蹊┐│╔╣¹Ż¼Å─Č°×ķ蹊┐Öz▓ņ└Ēšō║═Öz▓ņīŹ█`å¢Ņ}Ą─č▌▀MÜv│╠╠ß╣®╬─½Ių¦ō╬ĪŻČ■╩ŪĮyėŗ║¼ėąįōĻPµIį~Ą─╬─½IŲõ▒Š╔ĒĄ─ĻPµIį~╝░ŲõöĄ┴┐Ż¼Å─Č°¾w¼F╗∙ė┌įōĻPµIį~Ą─蹊┐ĘųŅÉŻ¼×ķ┴╦ĮŌ┼cįōÖz▓ņ└Ēšō║═Öz▓ņīŹ█`å¢Ņ}ŽÓĻPĄ─└Ēšō¾wŽĄ╠ß╣®╗∙ĄAĪŻę“┤╦Ż¼į┌Ī░蹊┐▀Mš╣Ī▒─ŻēKŽ┬蹊┐š▀┐╔ęįĄ├ĄĮįńŲ┌Öz▓ņ╬─½I┼┼├¹ĪóūŅą┬Öz▓ņ╬─½I┼┼├¹ęį╝░║╦ą─į~ģR┴ą▒ĒĪŻ
ĪĪĪĪŻ©Č■Ż®īWągė░Ēæ┴”
ĪĪĪĪīWągė░Ēæ┴”╩Ūęįė├æ¶▌ö╚ļĄ─║═Öz▓ņŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIį~Ż¼Å─ā╔éĆĘĮ├µ▀MąąöĄō■ĮyėŗŻ║ę╗╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½IĄ─▒╗ę²öĄ┴┐Ż¼Å─Č°¾w¼FįōŅÉ蹊┐Ą─īWągė░Ēæ┴”ĪŻČ■╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½IŽ┬▌döĄ┴┐Ż¼Å─Č°¾w¼Fī”įōŅÉ蹊┐Ą─ė├æ¶ĻPūóČ╚ĪŻę“┤╦Ż¼į┌Ī░īWągė░Ēæ┴”Ī▒─ŻēKŽ┬Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─ĮøĄõÖz▓ņ╬─½I║═¤ß³cÖz▓ņ╬─½IĪŻ
ĪĪĪĪŻ©╚²Ż®Ęų▓╝Ė┼ør
ĪĪĪĪĘų▓╝Ė┼ør╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻP╦č╦„į~ū„×ķĻPµIį~Ż¼Å─╦─éĆĘĮ├µ▀MąąöĄō■ĮyėŗŻ║ę╗╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½Iį┌Ė„─ĻČ╚Ą─Ęų▓╝ŪķørĪŻČ■╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½Iį┌Ė„ŅÉīW┐ŲĄ─Ęų▓╝ŪķørĪŻ╚²╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½Iį┌Ė„ŅÉŲ┌┐»Ą─Ęų▓╝ŪķørĪŻ╦─╩ŪĮyėŗŲ¬├¹ųą║¼ėąįōĻPµIį~Ą─Öz▓ņ╬─½Iį┌Ė„ŅÉÖCśŗĄ─Ęų▓╝ŪķørĪŻę“┤╦Ż¼į┌Ī░Ęų▓╝Ė┼ørĪ▒─ŻēKŽ┬蹊┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPÖz▓ņ╬─½IĄ──ĻČ╚Ęų▓╝ĪóīW┐ŲĘų▓╝ĪóŲ┌┐»Ęų▓╝║═ÖCśŗĘų▓╝ŪķørĪŻ
ĪĪĪĪŻ©╦─Ż®ŽÓĻPīWš▀
ĪĪĪĪŽÓĻPīWš▀╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻP╦č╦„į~ū„×ķĻPµIį~Ż¼░┤ššŽÓĻPÖz▓ņ╬─½I░l▒ĒĢrķgĪó▒╗ę²┤╬öĄ▀Mąą┼┼ą“Ż¼ęį▒Ńė├æ¶▓ķšęūŅįń╝░ūŅ╩▄ĻPūóÖz▓ņ╬─½IĄ─ū„š▀ĪŻ┤╦═ŌŻ¼░┤ššÖz▓ņ╬─½I░l╬─öĄ┴┐▀Mąą┼┼ą“Ż¼ęį▒Ńė├æ¶▓ķšę░l╬─öĄ┴┐ūŅČÓĄ─ū„š▀ĪŻę“┤╦Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─įńŲ┌īWš▀┼┼├¹ĪóīWš▀¤ßČ╚┼┼├¹ęį╝░Öz▓ņ╬─½I░l╬─┴┐┼┼├¹ĪŻ
ĪĪĪĪ═©▀^╔Ž╩÷ī”ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─═┌Š“Ż¼┐╔ęįÄ═ų·čąŠ┐š▀Å─▓╗═¼Ą─ĮŪČ╚┴╦ĮŌŽÓĻPÖz▓ņ└Ēšō║═Öz▓ņīŹ█`å¢Ņ}Ą─蹊┐Üv╩Ę║═¼FĀŅĪó蹊┐Ą─¤ßČ╚║═Ęų▓╝ŪķørŻ¼ęį╝░įōŅÉÖz▓ņ└Ēšō║═Öz▓ņīŹ█`蹊┐ųąĄ─┤·▒Ē╚╦╬’Ż¼Å─Č°×ķÖz▓ņ└Ēšō║═Öz▓ņīŹ█`蹊┐╣żū„Ą─ķ_š╣╠ß╣®ėą┴”Ūę┐╔┐┐Ą─Öz▓ņ╬─½Ių¦ō╬ĪŻ
ĪĪĪĪ╚²Īó┤¾öĄō■▒│Š░Ž┬┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─ķ_░l┼c└¹ė├
ĪĪĪĪ┼cĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½I▓╗═¼Ą─╩ŪŻ¼üĒūį╗ź┬ōŠW┤¾öĄō■▒│Š░Ž┬Ą─┴Ń┤╬öĄūų╗»Öz▓ņ╬─½Iätėą▓╗═¼Ą─ārųĄŻ║┴Ń┤╬Öz▓ņ╬─½IŠ▀ėąįŁ╔·ąįŻ¼╩Ū╚╦éāšµīŹęŌįĖĄ─ų▒Įė▒Ē¼FŻ╗┴Ń┤╬Öz▓ņ╬─½IŠ▀ėąśOÅŖĄ─Ģrą¦ąįŻ¼─▄ē“╝░ĢrĘ┤ė│«öŪ░Ą─ūŅą┬¤ß³c╝░äėæBŻ╗┴Ń┤╬Öz▓ņ╬─½IŠ▀ėąę╗Č©Ą─ŅA╩Š─▄┴”Ż¼ą┼Žóų▒ė^▒Ē╩÷Ą─▒│║¾┐╔─▄ŅA╩Šų°─│ĘN╔ą╬┤╦∙ų¬Ą─ÖC└ĒŻ╗┴Ń┤╬Öz▓ņ╬─½IŠ▀ėąÅVĘ║ąįŻ¼×ķ┐ńŅIė“蹊┐╠ß╣®┴╦╦╝┬ĘĪŻ
ĪĪĪĪ╗∙ė┌ĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─ārųĄŻ¼┐╔ęį×ķ蹊┐š▀ČÓĘĮ├µ┴╦ĮŌą┼ŽóĪóšŲ╬š┤¾▒ŖęŌęŖĪó┬Ā╚Ī▓╗═¼┬Ģę¶╠ß╣®ŲĮ┼_Ż¼Ą½ī”ė┌Š▀ėą┤¾öĄō■ī┘ąįĄ─┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IŻ¼ė╔ė┌Ųõ¾w┴┐┤¾Īó╦┘Č╚┐ņĪóą╬╩ĮČÓĪóļyūRäeĄ╚╠žš„Ż¼ätąĶę¬ė├┼cĘŪ┴Ń┤╬Öz▓ņ╬─½Iķ_░l┼c└¹ė├▓╗═¼Ą─ĘĮ╩ĮŻ¼└¹ė├ą┬┼dĄ─ŠWĮj┼└Žx╝╝ągĪóAPIĮė┐┌╝╝ągĄ╚ĘĮ╩Į▓╔╝»║══┌Š“ŽÓĻPĄ─Öz▓ņ╬─½IŠWĮjöĄō■ą┼ŽóŻ║Ųõę╗╩ŪŠWĮj┼└Žx╝╝ągĪŻį┌╗ź┬ōŠWųąŻ¼ŠWĒōų«ķg═©▀^│¼µ£Įė▒╦┤╦ŽÓ▀BŻ¼ą╬│╔ę╗éĆŠ▐┤¾Ą─ėąŽ“łDĪŻ└Ēšō╔ŽŻ¼ŠWĮj┼└ŽxęįHttpšłŪ¾Ą─ĘĮ╩Į½@╚Ī│§╩╝Ą─║═Öz▓ņ╬─½IŽÓĻPĄ─╗ź┬ōŠWĒō├µŻ¼▓óęį┤╦ū„×ķ│§╩╝╣سcŻ¼Ė∙ō■ŠWĒōų«ķgĄ─µ£ĮėĻPŽĄšęĄĮŲõ╦¹ŠWĒōŻ¼ų▄Č°Å═╩╝Ż¼Å─Č°īŹ¼F╚½ŠWą┼ŽóĄ─ūįäėūź╚Ī╣”─▄ĪŻ╚╗Č°Ż¼į┌īŹļHæ¬ė├ųąŻ¼═∙═∙▓╗┐╔─▄┼└╚ĪĄĮ╗ź┬ōŠW╔Ž║═Öz▓ņ╬─½IŽÓĻPĄ─╦∙ėąöĄō■ĪŻ═©│Ż▓╔ė├ÅVČ╚ā׎╚Īó╔ŅČ╚ā׎╚ĪóūŅ╝čā׎╚Ą╚╦č╦„▓▀┬įĪŻŲõČ■╩Ū APIĮė┐┌Ż©æ¬ė├│╠ą“Įė┐┌Ż¼Application Program InerfaceŻ®ĪŻAPIĮė┐┌╩Ūę╗ĮMČ©┴xĪó│╠ą“╝░ģfūhĄ─╝»║ŽŻ¼×ķ┴╦╣®Ą┌╚²ĘĮķ_░lš▀╩╣ė├Ż¼║▄ČÓ╗ź┬ōŠW╣½╦Šīóūį╝║Ą─ŠWšŠĘ■äšĘŌčb│╔ę╗ŽĄ┴ąAPIŻ¼╚ńą┬└╦╬ó▓®ĪóFacebookĪóČ╣░ĻĄ╚ĪŻė├涤oąĶ²ŗ┤¾Ą─ė▓╝■┼c╝╝ąg═Č┘YŠ═┐╔ęįĘĮ▒ŃĄ─ĮĶų·APIĮė┐┌═©▀^Č■┤╬ķ_░lĘĮ▒ŃĄž½@╚ĪĖ„ŅÉöĄō■ą┼ŽóŻ¼╚ń╬ó▓®▓®╬─Īó░l▓╝ĢrķgĪóĄž└Ē╬╗ų├Īó▓®ų„ą┼ŽóĪóĻPŽĄą┼ŽóĄ╚Ż¼ęį▒Ń▀Mąą╔Ņ╚ļĘų╬÷蹊┐ĪŻ┼c┼└Žx▄ø╝■ŽÓ▒╚Ż¼╩╣ė├APIĮė┐┌ļm╚╗▓╗ąĶę¬ųéĆĒō├µĄ─┼└╚ĪŻ¼½@╚Īą┼ŽóĖ³╝ėĘĮ▒ŃĪó£╩┤_Īó┐ņĮ▌ĪŻĄ½╩ŪAPIķ_Ę┼š▀ī”┘Yį┤įLå¢▀Mąą┴╦ę╗ŽĄ┴ąĄ─įOų├Ż¼╚ńą┬└╦╬ó▓®ī”▓╗═¼ė├æ¶Ą╚╝ēĄ─įLå¢Įė┐┌ÖÓŽ▐╝░Ņl┬╩Č╝▀Mąą┴╦Ž▐ųŲĪŻę“┤╦Ż¼▓╔ė├ā╔š▀ĮY║ŽĄ─ĘĮ╩Į┐╔ęįĖ³╝ėėąą¦Ą─½@Ą├ŽÓĻP┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IöĄō■[7]ĪŻ
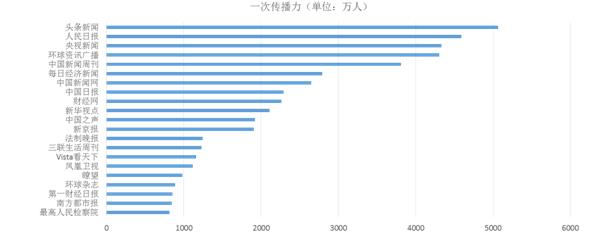
ĪĪĪĪį┌┤¾öĄō■▒│Š░Ž┬┴Ń┤╬öĄūų╗»Öz▓ņ╬─½Iį┌╗ź┬ōŠW╔ŽĄ─üĒį┤ų„ę¬ėą▓®┐═Īó╬ó▓®Īó╬óą┼ĪóŠS╗∙Īó▓ź┐═Īóšōē»Īóā╚╚▌╔ńģ^Ą╚╔ńĢ■╗»├Į¾wŻ¼▒Š╬─ų„ę¬ęį╬ó▓®öĄō■×ķ└²üĒĻU╩÷┴Ń┤╬öĄūų╗»Öz▓ņ╬─½I═┌Š“¾wŽĄŻ©╚ńłD3╦∙╩ŠŻ®Ż¼ŲõįŁę“į┌ė┌Ż║Ųõę╗Ż¼╬ó▓®ė├æ¶╗∙öĄ┤¾Ż¼ė╔ė┌╣”─▄▒ŃĮ▌Ą╚╠žš„Ż¼╬ó▓®ūįŲõ═Ų│÷▒ŃĄ├ĄĮ┴╦ÅVĘ║æ¬ė├Ż¼Įžų╣2016─Ļ6į┬╬ó▓®ė├æ¶ęÄ─Żęč▀_ĄĮ2.42ā|Ż¼▀@╩Ū│²╬óą┼ų«═ŌŲõ╦¹╔ńĢ■╗»├Į¾w¤oĘ©Ų¾╝░Ą─Ż╗ŲõČ■Ż¼╬ó▓®īŹĢrąįÅŖŻ¼┼c╬óą┼╦Į├▄Ą─╔ńĮ╗ī┘ąį▓╗═¼Ż¼╬ó▓®Š▀ėą├Į¾wī┘ąįŻ¼å╬Ž“Ė·ļSÖCųŲ╩╣Ą├ą┼ŽóĄ─½@╚Ī║═ĘųŽĒĖ³×ķ▒ŃĮ▌Ż¼Å─Č°╝ė╦┘┴╦ą┼ŽóĄ─┴„äėŻ¼ŲõīŹĢrąį║═¼Fł÷Ėą╔§ų┴│¼▀^┴╦Ųõ╦¹╚╬║╬├Į¾wŻ╗Ųõ╚²Ż¼╬ó▓®ą┼Žó┐╔▓╔╝»Ż¼═©▀^ŠWĮj┼└Žx╝╝ąg║═APIĮė┐┌ĘĮ╩Įė├æ¶┐╔ęį½@Ą├╦∙ąĶĄ─Ė„ŅÉ╬ó▓®ą┼ŽóŻ¼ŽÓ▒╚ų«Ž┬╬óą┼ė╔ė┌³cī”³c═©ą┼Ą─╦Į├▄ąį╝░ī”PCČ╦ų¦│ųĄ─ėąŽ▐ąįŻ¼╩╣Ųõļyęį½@Ą├╚½├µĄ─ą┼ŽóĪŻ
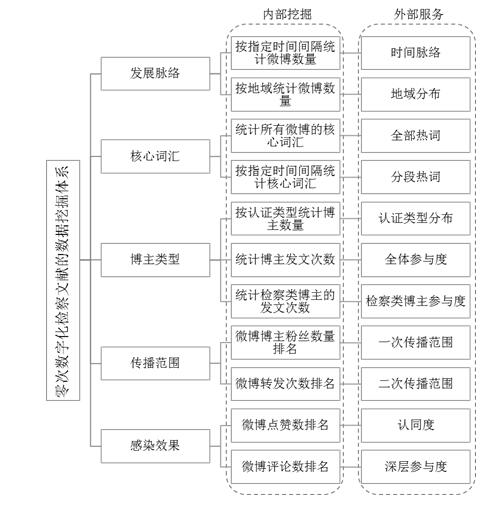
ĪĪĪĪłD3 ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄ
ĪĪĪĪŻ©ę╗Ż®░lš╣├}Įj
ĪĪĪĪ░lš╣├}Įjęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIūųŻ¼═©▀^Ī░┼└Žx▄ø╝■+APIĪ▒Įė┐┌Ą─ĘĮ╩Į┼└╚ĪĄ├ĄĮ╬ó▓®öĄō■║¾Ż¼ī”ŽÓĻP╬ó▓®░l▓╝Ģrķg╝░Ąžė“Ęųäe▀MąąĘų╬÷Ż¼ęį┴╦ĮŌ╬ó▓®ė├æ¶ī”įō║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╩┬╝■ĻPūó│╠Č╚ļSĢrķgĄ─ūā╗»ŪķørŻ¼Å─Č°═©▀^ĻPūóČ╚Ą─ūā╗»Ę┤═ŲĻPµIĢrķg╣سcŻ¼šęĄĮŲõ▒│║¾Ą─ė░Ēæę“╦žĪŻę“┤╦Ż¼čąŠ┐īWš▀┐╔ęįĄ├ĄĮ╩┬╝■ĻPūóČ╚Ą─Ģrķgū▀ä▌Ęų╬÷║═Ąžė“Ęų▓╝ŪķørĪŻ
ĪĪĪĪŻ©Č■Ż®║╦ą─į~ģR
ĪĪĪĪ║╦ą─į~ģRęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIūųŻ¼┼└╚ĪĄ├ĄĮ╬ó▓®öĄō■║¾Ż¼ī”╬ó▓®▀MąąĘųį~▓ó╠ß╚ĪŽÓĻP║╦ą─ĻPµIį~Ż¼╚╗║¾░┤ššė├æ¶ųĖČ©ĢrķgķgĖ¶▀MąąĘų╬÷Ż¼═©▀^ŪķĖąāAŽ“蹊┐░č╬š▌øšōäėŽ“╝░ĻPµI▐DŽ“³cĪŻę“┤╦Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─ĘųČ╬¤ßį~║═╚½▓┐¤ßį~ĪŻ
ĪĪĪĪŻ©╚²Ż®▓®ų„ŅÉą═
ĪĪĪĪ▓®ų„ŅÉą═╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIūųŻ¼┼└╚ĪĄ├ĄĮ╬ó▓®öĄō■║¾Ż¼ĘųŅÉĮyėŗ╬ó▓®▓®ų„į┌ą┬└╦ųąĄ─ė├æ¶ŅÉą═Ż¼╚ńéĆ╚╦šJūCĪóŲ¾śIšJūCĪóÖCśŗšJūC╗“ĘŪšJūCė├æ¶Ą╚Ż¼▓óī”Ė„ĘNŅÉą═Ą─▓®ų„Ą─ŽÓĻP╬ó▓®öĄ┴┐▀MąąĮyėŗŻ¼Å─Č°×ķĘų╬÷▓╗═¼ŅÉą═╬ó▓®▓®ų„Ż¼ė╚Ųõ╩ŪÖz▓ņÖCśŗį┌▌øšōč▌╗»▀^│╠ųąŲĄĮĄ─ū„ė├╠ß╣®ę└ō■ĪŻę“┤╦Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─╬ó▓®▓®ų„ŅÉą═Īóģó┼c│╠Č╚ęį╝░Öz▓ņŅÉ▓®ų„ģó┼cČ╚ĪŻ
ĪĪĪĪŻ©╦─Ż®é„▓źĘČć·
ĪĪĪĪé„▓źĘČć·╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIūųŻ¼┼└╚ĪĄ├ĄĮ╬ó▓®öĄō■║¾Ż¼ī”╬ó▓®▓®ų„Ą─Ę█ĮzöĄęį╝░įōŚl╬ó▓®Ą─▐D░löĄĘųäe▀MąąĮyėŗŻ¼ęį▒Ń┴╦ĮŌ╩┬╝■é„▓ź┬ĘÅĮŻ¼ī”ĻPµI╣سc▀Mąą╔Ņ╚ļĘų╬÷ĪŻę“┤╦Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─╬ó▓®▓®ų„Ę█ĮzöĄ┴┐┼┼├¹║═╬ó▓®▐D░löĄ┴┐┼┼├¹ĪŻ
ĪĪĪĪŻ©╬ÕŻ®Ėą╚Šą¦╣¹
ĪĪĪĪĖą╚Šą¦╣¹╩Ūęįė├æ¶▌ö╚ļĄ─║═Ī░Öz▓ņĪ▒ŽÓĻPĄ─╦č╦„į~ū„×ķĻPµIūųŻ¼┼└╚ĪĄ├ĄĮ╬ó▓®öĄō■║¾Ż¼ī”╬ó▓®Ą─³c┘ØöĄ╝░įušōöĄ▀MąąĮyėŗŻ¼ęį▒Ń┴╦ĮŌ▓╗═¼▓®ų„Ą─╬ó▓®ī”Ę█ĮzĄ─ė░Ēæ┴”ĪŻę“┤╦Ż¼čąŠ┐š▀┐╔ęįĄ├ĄĮ┼c▓ķšęā╚╚▌ŽÓĻPĄ─╬ó▓®³c┘ØöĄ┼┼├¹╝░įušōöĄ┼┼├¹ĪŻ
ĪĪĪĪ═©▀^ī”╔Ž╩÷ųĖś╦Ą─ĮyėŗĘų╬÷Ż¼┐╔ęįÄ═ų·čąŠ┐š▀Å─ČÓéĆĮŪČ╚┴╦ĮŌę╗Č©║═Ī░Öz▓ņĪ▒ŽÓĻP╩┬╝■Ą─░lš╣ŪķørŻ¼šŲ╬š▌øšōį┌╚╦ļHŠWĮjųąĄ─öU╔ó╝░ūā╗»▀^│╠Ż¼×ķ└ĒąįĘų╬÷╩┬╝■Īó╔Ņ╚ļ╠ĮīżÖC└Ē╠ß╣®╬─½I╗∙ĄAĪŻ
ĪĪĪĪ╦─Īó┤¾öĄō■▒│Š░Ž┬┴Ń┤╬┼cĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─Įyę╗ķ_░l┼cæ¬ė├Ī¬Ī¬ęįĪ░└ūč¾Ī▒░Ė╝■×ķ└²
ĪĪĪĪī”Öz▓ņ╬─½I┘Yį┤Ą─š¹║Ž┼cĘų╬÷╩Ūķ_š╣Öz▓ņ└Ēšō║═Öz▓ņīŹ█`蹊┐Ą─╗∙ĄA║═Ū░╠ߌl╝■ĪŻį┌┤¾öĄō■Ģr┤·öĄūų╗»Öz▓ņ╬─½I╝żį÷Ą─▒│Š░Ž┬Ż¼čąŠ┐š▀╗∙ė┌éĆ╚╦Ą─ĪóĘŪīŻśI╗»Ą─Ż¼Ūęßśī”ėąŽ▐╬─½I┘Y┴ŽĄ─š¹└ĒĘų╬÷Ż¼═∙═∙ī¦ų┬蹊┐īWš▀į┌ķ_š╣īWąg蹊┐ųąę╗ĘĮ├µę¬Å─╩┬┤¾┴┐Ą─Ū░Ų┌╬─½I£╩éõ╣żū„Ż╗┴Ēę╗ĘĮ├µŲõŲDļy╠Į╦„Ą─ĮY╣¹ę▓╬┤▒ž£╩┤_Ż¼└²╚ń▓╗═¼īWš▀ė^³cų«ķgĄ─ø_═╗Ą╚ĪŻę“┤╦Ż¼łDĢ°Ūķł¾å╬╬╗æ¬ęį┴Ń┤╬┼cĘŪ┴Ń┤╬öĄūų╗»Öz▓ņ╬─½IĄ─Įyę╗ķ_░l┼cæ¬ė├×ķ║╦ą─Ż¼į┌īŹ¼FĖ„ŅÉöĄūų╗»Öz▓ņ╬─½I┘Yį┤¤o┐pµ£ĮėĄ─╗∙ĄA╔ŽŻ¼śŗĮ©ųŪ─▄ų¬ūR╣▄└ĒŠWĮj║═éĆąį╗»ė├æ¶╣▄└Ē¾wŽĄŻ¼×ķ蹊┐š▀╠ß╣®ė╔³cĄĮ├µĪó╚½ĘĮ╬╗Īó┴ó¾w╗»Ą─ę╗šŠ╩Į╬─½IŠC║ŽĘ■äšĪŻŽ┬├µęįĪ░└ūč¾Ī▒░Ė╝■×ķ└²üĒ┐┤öĄūų╗»Öz▓ņ╬─½IĄ─Įyę╗ķ_░l┼cæ¬ė├ĪŻ
ĪĪĪĪĪ░└ūč¾Ī▒░Ė╝■╝■║åĮķŻ║└ūč¾Ż¼─ąŻ¼║■─ŽÕó┐h╚╦Ż¼ųąć°╚╦├±┤¾īWŁhŠ│īWį║2009╝ē┤T╩┐蹊┐╔·ĪŻ2016─Ļ5į┬7╚š═ĒŻ¼└ūč¾ļx╝ę║¾╔Ē═÷Ż¼▓²ŲĮŠ»ĘĮ═©ł¾ĘQŠ»ĘĮ▓ķ╠ÄūŃ»¤ĄĻ▀^│╠ųąŻ¼īóĪ░╔µŽėµ╬µĮĪ▒Ą─└ū─│┐žųŲ▓óĦ╗žīÅ▓ķŻ¼┤╦ķg└ū─│═╗╚╗╔Ē¾w▓╗▀mĮøōīŠ╚¤oą¦╔Ē═÷ĪŻ[8]
ĪĪĪĪŻ©ę╗Ż®ęįĪ░┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒═┌Š“Ī░└ūč¾Ī▒░Ė╝■ųą▓╗═¼ų„¾w╔µ╝░Ą─║╦ą─Ę©┬╔į~ģR
ĪĪĪĪ▒Š╬─ęįĪ░└ūč¾Ī▒ū„×ķĻPµIį~Ż¼└¹ė├┼└Žx▄ø╝■▓óĮY║ŽŠWšŠAPIĮė┐┌Ż¼┼└╚Ī2016─Ļ5į┬9╚š-7į┬3╚šą┬└╦╬ó▓®ą┼Žó╣▓329ŚlŻ¼ā╚╚▌░³└©╬ó▓®š²╬─Īó░l▓╝ĢrķgĪó░l▓╝ė├æ¶ID╝░ĻŪĘQĪó╬ó▓®▐D░l╝░įušōöĄĄ╚ų▒ĮėöĄō■Ż¼▓óį┌┤╦╗∙ĄA╔Ž▀Mę╗▓Įūź╚Ī╦∙ąĶĄ─ĻPŽĄöĄō■Ż¼╚ńĘ█Įzė├æ¶ą┼ŽóĪó▐D░l╗“įušōė├æ¶ą┼ŽóĄ╚ĪŻį┌½@Ą├╔Ž╩÷öĄō■ą┼Žóų«║¾Ż¼ĮĶų·Ī░┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒ųąĪ░║╦ą─į~ģRĪ▒Ęų╬÷─ŻēKŻ¼ī”öĄō■ą┼Žó▀MąąĘųį~ĪóŪÕŽ┤Ż¼┐╔Ą├ĄĮ╚ńłD4╦∙╩Š║╦ą─į~ģRłDūVŻ¼▓óīóŲõ░┤ššų„¾w▀Mąą│§▓ĮĘųŅÉ║¾Ą├ĄĮ╚ń▒Ē1╦∙╩ŠĄ─ĮY╣¹ĪŻ

ĪĪĪĪłD4 Ī░└ūč¾Ī▒░Ė╝■║╦ą─į~ģR
ĪĪĪĪ▒Ē1 Ī░└ūč¾Ī▒░Ė╝■ųą▓╗═¼ų„¾w╔µ╝░Ą─║╦ą─Ę©┬╔į~ģR

ĪĪĪĪÅ─▒Ē1┐╔ęį┐┤│÷Ī░└ūč¾Ī▒░Ė╝■ųą▓╗═¼Ą─Ę©┬╔ų„¾węį╝░Ųõ┐╔─▄╔µ╝░Ą─ų„ę¬Ę©┬╔å¢Ņ}ĪŻĮĶų·Ī░ĘŪ┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒ųąĪ░蹊┐▀Mš╣Ī▒─ŻēKŽ┬Ą─Ī░║╦ą─į~ģRĪ▒╣”─▄ęį╝░Ī░┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒ųąĪ░║╦ą─į~ģRĪ▒Ęų╬÷─ŻēK┐╔ęįĄ├ĄĮ┴Ń┤╬╝░ĘŪ┴Ń┤╬Öz▓ņ╬─½IĻPė┌Ī░└ūč¾Ī▒░Ė╝■Ą─║╦ą─į~ģRŻ¼▀MČ°×ķ╦ŠĘ©š▀╝░蹊┐š▀└ĒŪÕĪ░└ūč¾Ī▒░Ė╝■╦∙╔µ╝░Ą─Ę©┬╔ĻPŽĄŻ¼▓ķšęŽÓĻP╬─½I╠ß╣®ĻPµIį~ĪŻ
ĪĪĪĪŻ©Č■Ż®ęįĪ░ĘŪ┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒└ĒŪÕĪ░└ūč¾Ī▒░Ė╝■╦∙╔µĪ░µ╬µĮĪ▒å¢Ņ}Ą─蹊┐░lš╣├}Įj
ĪĪĪĪį┌Ī░└ūč¾Ī▒░Ė╝■ųąŻ¼╚ń╣¹čąŠ┐š▀ę¬čąŠ┐Ī░µ╬µĮĪ▒å¢Ņ}░lš╣Ą─Üv╩Ę├}ĮjŻ¼Š═┐╔ęįĮĶų·Ī░ĘŪ┴Ń┤╬Öz▓ņ╬─½IöĄō■═┌Š“¾wŽĄĪ▒│²┐╔Ą├ĄĮĪ░įńŲ┌╬─½IĪ▒ĪóĪ░ūŅą┬╬─½IĪ▒ęį╝░Ī░ĮøĄõ╬─½IĪ▒═ŌŻ¼└¹ė├ŲõųąĪ░Ęų▓╝Ė┼ørĪ▒─ŻēKŽ┬Ą─Ī░─ĻČ╚░l╬─┴┐Ī▒╝░Ī░蹊┐▀Mš╣Ī▒─ŻēKŽ┬Ą─Ī░║╦ą─į~ģRĪ▒╣”─▄┐╔ęįĄ├ĄĮĻPė┌▀@ę╗å¢Ņ}Üv╩ĘĻPūóŪķørŻ¼╚ńłD7╦∙╩ŠĪŻ
ĪĪĪĪŻ©aŻ®─ĻČ╚öĄ┴┐Ęų▓╝╝░į÷ķL┬╩

ĪĪĪĪŻ©bŻ®─ĻČ╚║╦ą─į~ģR
ĪĪĪĪłD5 ┼cĪ░µ╬µĮĪ▒ŽÓĻP╬─½IĄ─Üv╩ĘŪķør
ĪĪĪĪłD5▒Ē├„ßśī”Ī░µ╬µĮĪ▒Ą─å¢Ņ}蹊┐į┌▓╗═¼Ą─Üv╩Ę▒│Š░Ž┬╦∙╠ĮėæĄ─ųž³c▓╗═¼Ż¼Å─Č°┐╔ęįÄ═ų·čąŠ┐š▀└ĒŪÕĪ░µ╬µĮĪ▒å¢Ņ}Ą─蹊┐░lš╣├}ĮjĪŻ
ĪĪĪĪŻ©╚²Ż®ĮĶų·Ī░┴Ń┤╬╬─½IöĄō■═┌Š“¾wŽĄĪ▒└ĒŪÕĪ░└ūč¾Ī▒░Ė╝■Ą─░lš╣Üv│╠Ż║×ķÖz▓ņÖCĻP▌øŪķ▒O┐ž╝░▌øšōę²ī¦╠ß╣®ģó┐╝
ĪĪĪĪį┌Ī░└ūč¾Ī▒░Ė╝■ųąĮĶų·Ī░┴Ń┤╬╬─½IöĄō■═┌Š“¾wŽĄĪ▒┐╔ęįĖ³ŪÕ╬·Ą─└ĒŪÕ╩┬╝■Ą─░lš╣Üv│╠Ż¼Å─ČÓĘĮ╬╗ĪóČÓĮŪČ╚īÅęĢįō░Ė╝■ĪŻ
ĪĪĪĪ└¹ė├Ī░░lš╣├}ĮjĪ▒─ŻēKŽ┬Ą─Ī░Ģrķg├}ĮjĪ▒╣”─▄┐╔ęįī”ą┬└╦╬ó▓®ųąĄ─ŽÓĻP╬ó▓®öĄ┴┐▀MąąĮyėŗŻ¼Ą├ĄĮ╚ńłD6╦∙╩ŠĄ─ĮY╣¹ĪŻ═©▀^ĘĄ╦▌╬ó▓®ā╚╚▌┐╔ęįšęĄĮ═Ųäė╩┬╝■░lš╣Ą─ĻPµIŻ¼╚ń2016─Ļ5į┬9╚š└ūč¾╩┬╝■╩ū┤╬Ųž╣ŌŻ╗5į┬10╚š╬ó▓®╔Žķ_╩╝│÷¼FŽÓĻPĄ─ł¾Ą└Ż╗5į┬13╚šÅł╗▌Ū█Į╠╩┌ō·╚╬īŻ╝ęūC╚╦Ż╗5į┬19╚š▒▒Š®╩ą╣½░▓Šų═©▀^╬ó▓®░l▓╝└ūč¾░ĖŪķør═©ł¾Ż╗6į┬1╚š▒▒Š®╩ą╚╦├±Öz▓ņį║øQČ©ī”╔µ░ĖĄ─Š»▓ņ┴ó░Ėé╔▓ķŻ╗6į┬8╚š▒▒Š®ÖzĘĮ═©ł¾░Ė╝■ūŅą┬▐k└Ē▀Mš╣Ż╗6į┬27╚šī”└ūč¾╩¼¾wÖz“×ĶbČ©ĮYšō▀MąąīÅ▓ķšōūCŻ╗7į┬1╚š▒▒Š®╩ąÖz▓ņį║Ą┌╦─Ęųį║╣½▓╝╩¼ÖzĮY╣¹ĪŻ
ĪĪĪĪłD6 Ī░└ūč¾Ī▒░Ė╝■░lš╣Ģrķg├}ĮjłD
ĪĪĪĪ└¹ė├Ī░║╦ą─į~ģRĪ▒─ŻēKŻ¼╚ńłD4╝░▒Ē1╦∙╩ŠŻ¼┐╔ęį┴╦ĮŌ▌øšō¤ß³c╝░ū▀Ž“ĪŻ
ĪĪĪĪ└¹ė├Ī░▓®ų„ŅÉą═Ī▒─ŻēKŽ┬Ą─Ī░╚½¾wģó┼cČ╚Ī▒╝░Ī░Öz▓ņŅÉ▓®ų„ģó┼cČ╚Ī▒╣”─▄┐╔ęį┴╦ĮŌį┌╩┬╝■░lš╣▀^│╠ųąĖ„ŅÉ▓®ų„ī”╩┬╝■Ą─ĻPūó│╠Č╚Ż¼╚ńłD7╦∙╩ŠĪŻ
ĪĪĪĪŻ©aŻ®╚½¾w▓®ų„ģó┼cČ╚
ĪĪĪĪŻ©bŻ®Öz▓ņŅÉ▓®ų„ģó┼cČ╚
ĪĪĪĪłD7 Ī░└ūč¾Ī▒░Ė╝■ą┬└╦╬ó▓®▓®ų„ŅÉą═╝░ģó┼cČ╚
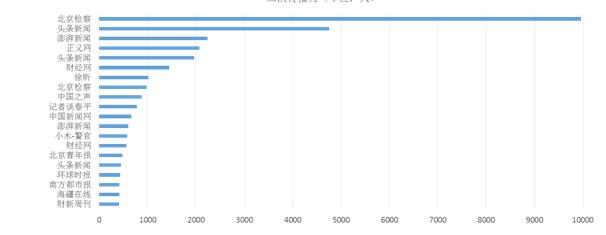
ĪĪĪĪ└¹ė├Ī░é„▓źĘČć·Ī▒─ŻēK┐╔ęį┴╦ĮŌ▓╗═¼▓®ų„Ą─ė░ĒæĘČć·ęį╝░▓╗═¼▓®╬─ę²ŲĄ─Ę█Įz▐D░lŪķørŻ¼╚ńłD8╦∙╩ŠĪŻ
ĪĪĪĪŻ©aŻ®ę╗┤╬é„▓źĘČć·
ĪĪĪĪŻ©bŻ®Č■┤╬é„▓źĘČć·
ĪĪĪĪłD8 Ī░└ūč¾Ī▒░Ė╝■ą┬└╦╬ó▓®é„▓źĘČć·
ĪĪĪĪ└¹ė├Ī░Ėą╚Šą¦╣¹Ī▒─ŻēK┐╔ęį┴╦ĮŌ▓╗═¼╬ó▓®ā╚╚▌╦∙ę²ŲĄ─╗źäėŪķørŻ¼Å─Č°¾w¼F▓®ų„Ą─Ėą╚Š┴”Ż¼╚ńłD9╦∙╩ŠĪŻ
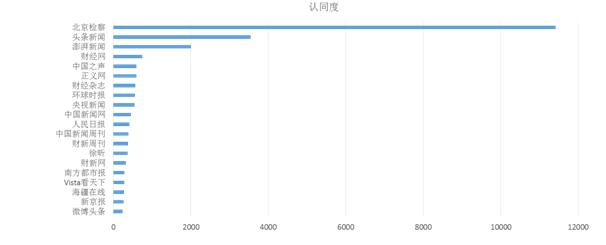
ĪĪĪĪŻ©aŻ®šJ═¼Č╚
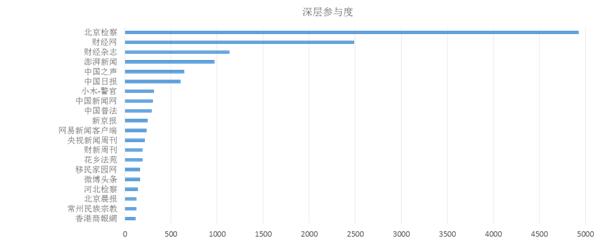
ĪĪĪĪŻ©bŻ®╔Ņīėģó┼cČ╚
ĪĪĪĪłD9 Ī░└ūč¾Ī▒╩┬╝■ą┬└╦╬ó▓®Ėą╚Šą¦╣¹
ĪĪĪĪĮĶų·╔Ž╩÷öĄō■═┌Š“ĮY╣¹Ż¼čąŠ┐īWš▀┐╔ęį╔Ņ╚ļĘų╬÷Ī░└ūč¾Ī▒╩┬╝■é„▓ź┬ĘÅĮ╝░▌øšōū▀Ž“Ż¼Å─Ȱ蹊┐▓╗═¼▓®ų„Īó▓╗═¼╬ó▓®ā╚╚▌ī”▌øšōĄ─ė░Ēæ─▄┴”Ż¼×ķ▌øŪķ▒O┐ž╝░▌øšōę²ī¦╠ß╣®ģó┐╝ĪŻ
ĪĪĪĪĮY šZ
ĪĪĪĪ┤¾öĄō■ī”Ģr┤·Ą─ė░Ēæ▓╗čįČ°ė„Ż¼Ųõ┼cÖz▓ņ└Ēšō┼cÖz▓ņīŹ█`Ą─╚┌║Ž┌ģä▌ę▓ųØu’@¼FŻ¼▓óĦüĒ┴╦ę╗ŽĄ┴ąą┬Ą─å¢Ņ}║═╠¶æĪŻ▒Š╬─ęį┤¾öĄō■ī”öĄūų╗»Öz▓ņ╬─½Iķ_░l┼c└¹ė├Ą─ė░Ēæū„×ķŪą╚ļ³cŻ¼╠Įėæ┴╦╚ń║╬ßśī”┤¾öĄō■╠žš„┼cĢrŠŃ▀Mķ_░l┼c└¹ė├öĄūų╗»Öz▓ņ╬─½IĄ─å¢Ņ}ĪŻ╣Pš▀ßśī”▀@ę╗å¢Ņ}Ą─╦╝┐╝Ż¼ų„ę¬ų°č█ė┌æ┬į┬ĘÅĮ╝░╝╝ągīŹ¼FĪŻ╚╗Č°Ż¼Öz▓ņ╬─½IĄ─╣▄└ĒĪóķ_░l┼c└¹ė├ļx▓╗ķ_╚╦ĪóžöĪó╬’Ą─ų¦ō╬Ż¼ąĶę¬ę╗┼·╝╚Š½═©Öz▓ņśIäšėųŠ▀ėą┤¾öĄō■╦╝ŠSĪó╔Ųė┌╬─½I╣▄└ĒĄ─Å═║Žą═╚╦▓┼Ż╗ę▓ąĶꬊ▀ėąįŲ┤µā”║═įŲėŗ╦Ń─▄┴”Ą─ŽĄĮyŲĮ┼_Ą╚ĪŻų╗ėąīóÖz▓ņ╬─½Iķ_░l┼c└¹ė├║├Ż¼▓┼─▄×ķÖz▓ņ╣żū„┐ŲīW░lš╣╠ß╣®Ė³ČÓĄ─ųŪ┴”ų¦│ųĪŻ