Į³─ĻüĒŻ¼ļSų°╬ęć°ĮøØ·Ą─░lš╣Ż¼ŁhŠ│å¢Ņ}╚šØu═╗│÷Ż¼Ų¾śI▀`Ę©┼┼╬█ī¦ų┬ć└ųž╬Ż║”╚║▒Ŗ╔·«a╔·╗ŅĄ─╩┬╝■Ģrėą░l╔·Ż¼ėąĻPŁhŠ│▒ŻūoĄ─ę╗ą®╗∙▒ŠĖ┼─Ņ▒╗╩╣ė├Ą├▒╚▌^üyŻ¼×ķ┴╦Ė³║├ĄžĘĮ▒ŃÅV┤¾Łh▒Ż╣żū„š▀į┌śIäš╣żū„ųą╩╣ė├Ę©┬╔Ę©ęÄŻ¼╚ń║╬īŹ¼FųŪ─▄æ¬ė├Öz╦„æ¬ė├Ż¼ęŌ┴xĘŪ│Żųžę¬ĪŻųŪ─▄Öz╦„╩Ū╗∙ė┌ūį╚╗šZčįĄ─Öz╦„ą╬╩ĮŻ¼ÖCŲ„Ė∙ō■ė├æ¶╦∙╠ß╣®Ą─ęįūį╚╗šZčį▒Ē╩÷Ą─Öz╦„ę¬Ū¾▀MąąĘų╬÷Ż¼Č°║¾ą╬│╔Öz╦„▓▀┬į▀Mąą╦č╦„ĪŻė├æ¶╦∙ąĶę¬ū÷Ą─āHāH╩ŪĖµįVėŗ╦ŃÖCŽļū÷╩▓├┤Ż¼ų┴ė┌į§śėīŹ¼Fät¤oĒÜ╚╦╣żĖ╔ŅAŻ¼▀@ęŌ╬Čų°ė├æ¶īóÅžĄūÅ─Ę▒¼ŹĄ─ęÄätųąĮŌ├ō│÷üĒĪŻ[1]
1.▒ŠšnŅ}ć°ā╚═Ō蹊┐¼FĀŅ┼c┤µį┌Ą─å¢Ņ}
─┐Ū░╩╣ė├▌^×ķ┤¾▒ŖŲš▒ķĄ─Öz╦„ŽĄĮyę╗░ŃČ╝╩Ūė╔╚²éĆ╗∙▒Š─ŻēKĮM│╔Ż║öĄō■Ą─Öz╦„ĪóÖz╦„║¾ī”ŲõÖz╦„ĮY╣¹Ą─╠Ä└Ē║═ī”öĄō■ÄņĄ─ŠSūoĪóöĄō■Äņ─ŻēKų„꬞ōž¤Į©┴óŅ}õøĪó╬─š¬╝░╚½╬─ÄņŻ¼Į©┴ó╦„ę²║═Ą╣┼┼╬─ÖnĄ╚Ż¼Ųõ╔·│╔Ą─Ą╣┼┼Ön╩Ūė╔╚╦╣ż│ķį~╗“░ļūįäė╗»ś╦ę²Č°│╔Ż¼╝┤╩╣ė╔ėŗ╦ŃÖC╚½ūįäėś╦ę²Ż¼ś╦ę²ę▓╩Ū╗∙ė┌╬─▒Šūų┤«Ą─║åå╬Īóų▒ė^Ą─ę²ė├Ż╗Öz╦„─ŻēKų„꬞ōž¤į┌ę╗Č©▀ē▌ŗŚl╝■Ž┬Ż¼į┌╦∙ėąŽÓĻPĄ─Äņ╝»║ŽĘČć·ā╚▓ķšę╦∙ąĶą┼ŽóŻ╗ĮY╣¹╠Ä└Ē─ŻēKžōž¤╠ßĮ╗ĮY╣¹ł¾Ėµ▓ó▌ö│÷Öz╦„ĮY╣¹Įoė├æ¶ĪŻ[2]
į┌«öŽ┬Ą─Öz╦„ŽĄĮyų„ę¬╩Ūęį╬─ūųą═ą┼ŽóÖz╦„×ķų„Ż¼ī”łDą╬ą┼ŽóĪółDŽ±ą┼ŽóĪó┬Ģ궹┼ŽóĄ╚Öz╦„─▄┴”Äū║§×ķ┴ŃŻ¼Č°Ūę┤¾ČÓöĄŽĄĮyę╗░Ń▓╔ė├Ą─╩Ū╩▄┐ž╗“š▀░ļ╩▄┐žś╦ę²šZčįą═Öz╦„Ż¼ŲõÖz╦„ą¦┬╩═∙═∙╩Ū▓╗▒M╚╦ęŌŻ¼Č°Ųõį┌║▄┤¾│╠Č╚╔ŽÖz╦„ą¦┬╩╚į╚╗╚ĪøQī”ė┌ų„Ņ}į~šZĄ─┐žųŲĪŻ[3]
1.1ųŪ─▄Öz╦„ŽĄĮyĄ─░lš╣蹊┐
Å─1956─Ļ╚╦╣żųŪ─▄▒╗š²╩Į╠ß│÷Ż¼ęčĮøėą┴╦40─ĻÜv╩ĘĪŻėóć°öĄīW╝ęĪó▀ē▌ŗīW╝ęłDņ`Ż©TuringŻ®▒╗╩└╚╦ĘQ×ķ╚╦╣żųŪ─▄ų«ĖĖŻ¼▓╗āHāH╩Ūė╔ė┌╦¹äōįņ┴╦ę╗éĆ║åå╬Č°ėų═©ė├Ą─ĘŪöĄūųĄ─ėŗ╦Ń─Żą═Ż¼Č°Ūę╦¹▀Ćų▒ĮėūC├„┴╦ėŗ╦ŃÖC╩Ūėą┐╔─▄ęį─│ĘN▒╗└ĒĮŌ×ķųŪ─▄▓óĮė╩▄Ą─ĘĮĘ©╣żū„ĪŻ[4]┘MĖ∙§U─ĘŻ©FeigenbaumŻ®čąŠ┐ąĪĮMė┌1968─Ļ│╔╣”蹊┐┴╦Ą┌ę╗éĆīŻ╝ꎥĮyĘQ×ķDENDRALDudaŻ©Č┼▀_Ż®ķ_░lĄ─PROSPECTORĄž┘|┐▒╠ĮīŻ╝ꎥĮy▀Ćėą▒╚▌^ėą┤·▒ĒąįĄ─×ķŲ¾śIė├æ¶┌A╚ĪŠ▐┤¾ĮøØ·ą¦ęµĄ─RI╔╠ė├īŻ╝ꎥĮyĄ╚ĪŻ
20╩└╝o80─Ļ┤·Ż¼īŻ╝ꎥĮyĄ├ĄĮ┴╦┼Ņ▓¬░lš╣Ż¼┼c┤╦═¼Ģrų¬ūR╣ż│╠Ą─čĖ╦┘░lš╣ę▓į┌╚½Ū“š╣ķ_ĪŻ╚╗Č°ĄĮ20╩└╝o80─Ļ┤·║¾Ų┌Ż¼╚╦╣żųŪ─▄Ą─░lš╣ė÷ĄĮ┴╦ć└Š■Ą─╠¶æ║═└¦ļyŻ¼ė╔ė┌æ¬ė├ŅIė“Ą─¬MšŁ║═│ŻūRų¬ūRĄ─╚▒Ę”╩╣Ą├ŅAŲ┌─┐ś╦¤oĘ©īŹ¼FŻ¼└¦ļyĘ┤æ¬│÷╚╦╣żųŪ─▄┼cų¬ūR╣ż│╠ę╗ą®Ė∙▒ŠąįĄ─å¢Ņ}Ż¼╚ńĮ╗╗źĪóöUš╣┼c¾wŽĄĄ╚å¢Ņ}ų▒ĄĮ¼Fį┌ę▓╩Ū╬ęéāśO┴”╠Įėæ║═ĮŌøQĄ─šnŅ}ų«ę╗ĪŻ[5]
1.2┤µį┌Ą─å¢Ņ}
─┐Ū░Ųš▒ķ╩╣ė├Ą─Öz╦„ŽĄĮyŻ¼┼c20╩└╝o80─Ļ┤·ŽÓ▒╚ļm╚╗ėą┴╦▒╚▌^┤¾Ą─▀M▓ĮŻ¼ŽĄĮyęčĮø╚┌╚ļ┴╦▒╚▌^│Żė├Ą─Öz╦„╝╝ąg╚ń╣╠Č©į~ĮMĪó▓╝Ā¢▀\╦ŃĪó▀ē▌ŗ▀\╦ŃĄ╚Ż¼╗∙▒Š╔ŽØMūŃ┴╦¼Fėąė├æ¶Ą─Öz╦„ąĶŪ¾Ż¼Ą½╚į╚╗┤µį┌ųTČÓ▓╗ūŃų«╠ÄŻ¼ąĶę¬▀MąąĖ─▀M╝ėęį═Ļ╔ŲŻ║
Ż©1Ż®öĄō■Äņį~Ąõ╩šõøĄ─į~Śl▒╚▌^╔┘Ż¼Å─Č°╚▒Ę”ÅVĘ║Č°ėų╚½├µĄ─öĄō■Į╗▓µś╦ę²ĪŻ
Ż©2Ż®Öz╦„ŽĄĮy╚▒Ę”▌^ÅŖĄ─ūįīW┴Ģ╣”─▄ĪŻ
Ż©3Ż®¼FėąĄ─Öz╦„ŽĄĮyĄ─šZ┴xĘų╬÷ī”ė┌═¼┴x╗“š▀ŽÓĮ³Ą─öĄō■Īóā╚╚▌Ęų╬÷─▄┴”╗∙▒Š╔Ž╩Ū▓╗Š▀éõĄ─Ż¼šZ┴xĄ─═¼Ą╚╠Ä└Ē─▄┴”śOĄ═╗“š▀Š═▓╗─▄▀Mąą╠Ä└ĒŻ¼ę“┤╦ķ_░lšZ┴xÖz╦„ūRäeŽĄĮyŻ¼▓┼─▄Ė³║├ĄžīŹ¼FŽĄĮyųŪ─▄╗»Ż¼▓┼─▄╩╣ķgĮė▓ķįāĖ³╚½├µĪóĖ³ŽĄĮyĪóĖ³ÅžĄūĪŻ[6]
Ż©4Ż®öĄō■ÄņŽĄĮyŅÉą═▒╚▌^╚▒Ę”ąĶ▓╗öÓžSĖ╗Ż¼ŽĄĮyĄ─öĄō■ĮYśŗąĶ▓╗öÓ╝ėęįĖ─▀Mį┌ĻPŽĄą═öĄō■ÄņĄ─╗∙ĄA╔ŽŻ¼ūóųžī”├µŽ“ī”Ž¾ą═ĪóČÓ├Į¾wą═Īóą┬ą═Ą─╝»│╔öĄō■ÄņĄ─ķ_░lĪŻ[7]
2.ū„š▀Ą─ė^³c║═ų„ę¬ķ_░l╦╝┬Ę
ŁhŠ│▒ŻūoĘ©┬╔Ę©ęÄųŪ─▄Öz╦„╩Ūī”¼Fėąé„ĮyÖz╦„ŽĄĮyĄ─ę╗ą®▓╗ūŃ▀MąąĖ─▀MŻ¼╠žäe╩Ūį┌ą┼ŽóÖz╦„▀^│╠ųąŻ¼ę²╚ļ┴╦ī”Ž¾Ė┼─ŅÅ─Č°┤¾┤¾╠ßĖ▀┴╦šZ┴xą┼ŽóĄ─▓ķįā╠Ä└Ē─▄┴”ĪŻ×ķ┴╦ī”Ųõą┼ŽóÖz╦„ąį─▄╝ėęįĖ─╔ŲŻ¼▒žĒÜ╠ßĖ▀ą┼ŽóÖz╦„╦ŃĘ©Ą─▓ķ╚½┬╩┼c▓ķ£╩┬╩Ż¼ę▓Š═╩Ūšf▒žĒÜ═©▀^ī”šZ┴xĘų╬÷Īóūįäė▓ķįāöUš╣Ą╚╠Ä└Ē▓┘ū„▀MąąĖ─┴╝Ī░Ė─╔ŲĪ▒ĪŻ[8]
▒ŠŽĄĮyū„×ķę╗éĆųŪ─▄Öz╦„ę²ŪµŻ¼į┌╣”─▄╔Ž│²Š▀éõę╗ą®╗∙▒Š╣”─▄═ŌŻ¼▀Ćæ¬įōį┌ę╗ą®╣”─▄╔Žā×ė┌¼FėąŽĄĮyĪŻ[9]į┌▒ŠŽĄĮy«öųą¾w¼F×ķ╚ńŽ┬Äū³cŻ║
Ż©1Ż®į┌šZ┴xĘų╬÷─▄┴”╔Žā×ė┌¼FėąŽĄĮyŻ¼▓óŠ▀ėąę╗Č©ūįäė▓ķįāöUš╣ĪóšZ┴x═Ų└ĒĄ╚╣”─▄ĪŻ
Ż©2Ż®öĄō■Äņ╩šõøĄ─╗∙ĄAą┼Žóæ¬▓╗öÓĖ³ą┬Ż¼▒ŻūCį┌ŁhŠ│▒ŻūoĘ©┬╔Ę©ęÄŅIė“└’Ż¼Ųõą┼ŽóĄ─╚½├µ┼c£╩┤_ĪŻ
Ż©3Ż®ā×╗»ŽĄĮy║═ė├æ¶Į╗╗ź╦ŃĘ©Ż¼īŹ¼FŲõ─▄▀MąąĖ▀│╠Č╚Ą─╗ź▓┘ū„Ż¼ī”ė├æ¶╦∙ąĶ▓ķįāĄ─ą┼Žó▒ŻūC£╩┤_║å├„Č¾ę¬ĪŻ
Ż©4Ż®┐╝æ]ĄĮ▒ŠŽĄĮyĄ─╠ž╩ŌąįŻ¼ī”ė├æ¶Öz╦„ĮY╣¹æ¬ų¦│ųČÓĘN┼┼ą“ĘĮ╩ĮŻ¼╚ń░┤Ę©┬╔Ę©ęÄĄ─ųŲČ©Ģrķg┼┼ą“║═░┤┼c▓ķįāŚl╝■Ą─ŽÓ╦ŲČ╚┼┼ą“Ą╚ĪŻ
3.ŁhŠ│▒ŻūoĘ©┬╔Ę©ęÄųŪ─▄Öz╦„ŽĄĮyĄ─įOėŗĘų╬÷┼cīŹ¼FĘĮĘ©
3.1ŽĄĮyįOėŗĄ─ĮYśŗ
▒ŠųŪ─▄ą┼ŽóÖz╦„ŽĄĮyĮYśŗ║═╣żū„įŁ└Ē╚ńłD1╦∙╩Š
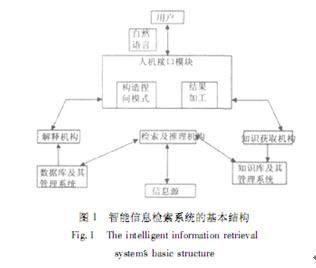
Ż©1Ż®╚╦ÖCĮė┐┌─ŻēKę╗░Ńė├üĒūīė├æ¶┼cą┼ŽóÖz╦„
ŽĄĮy▀MąąĮ╗┴„Ą─Įń├µĘQŲõ×ķ╚╦ÖCĮė┐┌Ż¼╦³┐╔ęįī”ė├æ¶Ą─ūį╚╗šZčį╠ßå¢▀MąąĘų╬÷Īó└ĒĮŌŻ¼▓óĮo│÷▀m║Žė├æ¶Ą─ĮY╣¹Ż¼▓óŪę▒Š─ŻēK▀ĆŠ▀ėąĮŌßī╣”─▄ĪŻ╚╦ÖCĮė┐┌─ŻēKė╔ę╗ĮM│╠ą“║═ī”æ¬Ą─ė▓╝■ĮM│╔Ż¼▌ö╚ļ▌ö│÷╣żū„Š═╩Ūė├╦³üĒ═Ļ│╔Ą─ĪŻ
Ż©2Ż®ų¬ūRÄņ╝░Ųõ╣▄└ĒŽĄĮy─ŻēK
ų¬ūRÄņę▓Š═╩Ū═©│Ż╦∙šfĄ─ų¬ūR┤µā”ÖCśŗŻ¼ė├ė┌┤µā”īŻ╝ęĄ─Įø“׹įų¬ūR┼cĮŌøQė├æ¶ą┼ŽóąĶŪ¾╦∙ąĶꬥ─įŁ└Ēąįų¬ūR╝░ėąĻPĄ─╩┬īŹĄ╚ĪŻ
Ż©3Ż®öĄō■Äņ╝░Ųõ╣▄└ĒŽĄĮy─ŻēK
ė├üĒ┤µĘ┼ė├æ¶╦∙╠ß╣®Ą─│§╩╝öĄō■╗“š▀╩┬īŹĪóī”å¢Ņ}Ą─├Ķ╩÷ęį╝░š¹éĆŽĄĮy▀\ąą▀^│╠ųą╦∙Ą├ĄĮĄ─▀\ąąą┼ŽóĪóųąķgĮY╣¹öĄō■ęį╝░ūŅĮKĮY╣¹öĄō■Ą╚ĪŻ
Ż©4Ż®Öz╦„═Ų└ĒÖCśŗ─ŻēK
Öz╦„═Ų└Ē─ŻēK╩Ūę╗éĆųŪ─▄Öz╦„ŽĄĮyĄ─║╦ą─Ż¼╩Ū░┤ššę╗Č©Ą─▓▀┬į═Ų└Ēī”Ųõė├æ¶╠ß│÷å¢Ņ}▀MąąĮŌøQŻ¼Ųõ▓╗āHę¬ī”ų¬ūRÄņųąĄ─ų¬ūR╝ėęį└¹ė├Ė³ūóųžī”Ė„ĘN═Ų└Ē╝╝ągĪóą┼ŽóÖz╦„▓▀┬įĄ─ŠC║Žæ¬ė├ĪŻ
Ż©5Ż®ų¬ūR½@╚ĪÖCśŗ─ŻēK
ų¬ūR½@╚ĪÖCśŗį┌▒ŠŽĄĮyĄ─╣”─▄╩Ū═©▀^│╠ą“═Ļ│╔ī”ŽĄĮyĄ─ūį╬ęīW┴Ģ╣”─▄Ż¼▒ŻūCŽĄĮyų¬ūRÄņĄ─ąį─▄┴╝║├Ż¼ī”ų¬ūR¾wŽĄĄ─═Ļš¹ąį┼cĮyę╗ąį╝ėęįŠSūoĪŻ
Ż©6Ż®ĮŌßīÖCśŗ─ŻēK
ĮŌßīÖCśŗĄ─ų„ę¬┬Ü─▄Š═╩Ū×ķ╚╦ÖC╠ß╣®ę╗éĆ┴╝║├Ą─Į╗╗źŲĮ┼_Ż¼į┌ī”ūį╬ęäėū„ĪóĘ┤æ¬ū„│÷ĮŌßīĄ─═¼Ģrę▓═¼śė╗ž┤ė├æ¶╠ß│÷Ą─ŽÓĻPå¢Ņ}Ż¼ĮŌßīÖCśŗ╩Ūą┼ŽóÖz╦„ŽĄĮy┼cė├æ¶Į╗┴„Ą─ų„ę¬Ū■Ą└Ż¼ę▓╩Ū╚Īą┼ė┌ė├æ¶Ą─ę╗éĆĘŪ│Żųžę¬Ą─┤ļ╩®ĪŻ
3.2▒ŠųŪ─▄Öz╦„ŽĄĮy▓╔ė├Ą─īŹ¼FĘĮĘ©
▒ŠŽĄĮy蹊┐ęįą┼Žó╣▄└Ēų¬ūR×ķ╗∙ĄA└ĒšōŻ¼ęįŽĄĮy┐ŲīWĄ─ė^³c×ķųĖī¦Ż¼ęįJavašZčį║═MySQLöĄō■Äņū„×ķ╣żŠ▀Īóš¹¾wįOėŗę└šš▄ø╝■╣ż│╠Ą─ĘĮĘ©Ż¼Įø▀^ąĶŪ¾Ęų╬÷Īó┐é¾wįOėŗĪó╬─Ön║═┤·┤aĄ─ŠÄųŲĪó─ŻēK£yįć║═ŽĄĮyīŹ¼FÄūéĆļAČ╬Ż¼▀Mąą▒ŠŽĄĮyĄ─ķ_░lĪŻŽ┬├µī”ķ_░lŁhŠ│▀Mąą║åę¬Ė┼╩÷ĪŻ
MyEclipseŻ¼╩Ūę╗éĆ╩«Ęųā׹ѥ─ė├ė┌ķ_░lJavaŻ¼J2EEĄ─Eclipse▓Õ╝■╝»║ŽŻ¼╩Ūī”EclipseIDEĄ─öUš╣Ż¼└¹ė├╦³┐╔ęįį┌öĄō■Äņ║═JavaEEĄ─ķ_░lĪó░l▓╝Ż¼ęį╝░æ¬ė├│╠ą“Ę■äšŲ„Ą─š¹║ŽĘĮ├µśO┤¾Ą─╠ßĖ▀╣żū„ą¦┬╩╦³╩Ū╣”─▄žSĖ╗Ą─JavaEE╝»│╔ķ_░lŁhŠ│Ż¼░³└©┴╦═ĻéõĄ─ŠÄ┤aš{įć£yįć║═░l▓╝╣”─▄Ż¼═Ļš¹ų¦│ųHTMLŻ¼StrutsŻ¼JSPŻ¼CSSŻ¼JavascriptŻ¼SQLŻ¼HibernateĪŻ
MySQL╩Ūę╗éĆŠ½Ū╔Ą─SQLöĄō■Äņ╣▄└ĒŽĄĮyŻ¼ė╔ė┌╦³Ą─╣”─▄ÅŖ┤¾Īó╩╣ė├║å▒ŃĪó╣▄└ĒĘĮ▒ŃĪó▀\ąą╦┘Č╚┐ņŻ¼░▓╚½┐╔┐┐ąįÅŖĪóņ`╗ŅžSĖ╗Ą─æ¬ė├ŠÄ│╠Įė┐┌Ż©APIŻ®ęį╝░Š½Ū╔Ą─ŽĄĮyĮYśŗĪŻ
3.3▒ŠÖz╦„ŽĄĮy╣”─▄─ŻēKįOėŗ
Ė∙ō■ŽĄĮyĘų╬÷įOėŗĄ─ę╗░ŃĘĮĘ©┼c─ŻēKäØĘųĄ─įŁätŻ¼═¼Ģr╝µŅÖė├æ¶ęū▓┘ū„ąįŻ¼╬ęéāīóŽĄĮy╣”─▄─ŻēKäØĘų×ķ╚ńłD2╦∙╩ŠŻ║
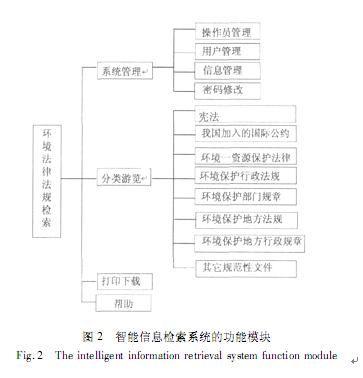
3.4öĄō■ÄņĄ─Į©┴ó┴„│╠
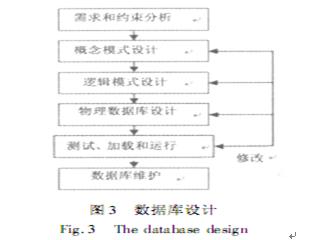
öĄō■ÄņįOėŗĄ─ę╗░Ń┴„│╠╚ńłD3╦∙╩ŠŻ¼╣▓Ęų┴∙éĆļAČ╬Ż║ąĶŪ¾║═╝s╩°Ęų╬÷Ż╗Ė┼─Ņ─Ż╩ĮįOėŗŻ╗▀ē▌ŗ─Ż╩ĮįOėŗŻ╗╬’└ĒöĄō■ÄņįOėŗŻ╗£yįćĪó╝ė▌d║═▀\ąąŻ╗öĄō■ŠSūoŲõųąĄ┌2Īó3Īó4╚²éĆļAČ╬×ķöĄō■ÄņįOėŗ▀^│╠Ż¼▀@╩Ūę╗éĆĘ┤Å═Ą³┤·ų▒ų┴▀_ĄĮįOėŗ─┐ś╦Ą─▀^│╠ĪŻ[10]
Ż©1Ż®ąĶŪ¾║═╝s╩°Ęų╬÷ļAČ╬░³└©Ż║š{▓ķė├æ¶ę¬Ū¾Ż╗Ęų╬÷öĄō■Ą─¼FĀŅŻ╗Ęų╬÷öĄō■Ą─╩╣ė├Ż╗┤_Č©ŁhŠ│╝s╩°Śl╝■Ż╗▀xō±öĄō■Äņ╣▄└ĒŽĄĮy╗“蹊┐¼FėąöĄō■Äņ╣▄└ĒŽĄĮyĄ─╣”─▄┼cąį─▄Ż╗╠ß│÷ąĶŪ¾║═╝s╩°Ęų╬÷ł¾ĖµöĄō■ūųĄõĪŻ
Ż©2Ż®Ė┼─Ņ─Ż╩ĮįOėŗļAČ╬░³└©Ż║īŹ¾w╝»║ŽŻ╗īŹ¾wĮYśŗĄ─µIŻ╗īŹ¾wĄ─ī┘ąįŻ╗ė“╝»║ŽĄ╚ĪŻ
Ż©3Ż®▀ē▌ŗ─Ż╩ĮįOėŗļAČ╬░³└©Ż║ĻPŽĄŻ©▒ĒĖ±Ż®Ą─╝»║ŽŻ╗ĻPŽĄĄ─ī┘ąįŻ╗ų„µIŻ╗┤╬µIŻ╗═ŌµIŻ╗ė“╝»║ŽŻ╗╦„ę²╝░µ£┬ĘĄ╚ĪŻ
Ż©4Ż®╬’└ĒöĄō■ÄņįOėŗļAČ╬░³└©Ż║┤_Č©╬─╝■Ą─┤µā”ĮYśŗŻ©Ēśą“ĮYśŗĪóļSÖCĮYśŗĪó╦„ę²Ēśą“ĮYśŗĪó▒ĒĮYśŗĪóöĄĮYśŗŻ®Ż╗▀x╚Ī┤µ╚Ī┬ĘÅĮĮYśŗŻ©ŽĄĮYśŗĪóµ£┬ĘĮYśŗŻ®Ż¼┤µ╚Ī╦ŃĘ©Ż¼┤╬╝ē┤µ╚ĪĮYśŗŻ©╔ó┴ąĪó┤╬╝ē╦„ę²Ż®Ż╗╬─╝■ū„┤╣ų▒Ęų╗»╗“╦«ŲĮĘų╗»Ż¼┤_Č©┤µā”įOéõŻ╗┤_Č©öĄō■ēKęÄ─ŻŻ╗┤_Č©ŠÅø_ģ^ęÄ─ŻŻ╗┤_Č©öĄō■Äņ┤µā”┐šķg┐éęÄ─ŻĪŻ
╬ęéā═©▀^öĄō■ÄņįOėŗ┴„│╠ī”¼FėąĄ─ŁhŠ│▒ŻūoĘ©┬╔Ę©ęÄ▀Mąąīė┤╬ĻPŽĄ─Żą═š¹└Ē║¾═©▀^ę╗Č©Ą─ĘĮĘ©ī¦╚ļĄĮMySQLöĄō■ÄņųąŻ©▀@└’═©▀^Ž╚ī¦│÷öĄō■ÄņSQL─_▒Šį┘ī¦╚ļĄ─ĘĮĘ©Ż®Ż¼═¼Ģrę▓ė├ĄĮ┴╦phpMyAdmin╣▄└Ē╣żŠ▀ĪŻ
4.š╣═¹
═©▀^ī”ŁhŠ│▒ŻūoĘ©┬╔Ę©ęÄųŪ─▄Öz╦„ŽĄĮyĄ─ķ_░l╠Ņča┴╦¼FėąĄ─▓╗ūŃ┼c┐š╚▒Ż¼╗∙▒Š┐╔ęįØMūŃ¼Fį┌ė├æ¶Ą─ąĶŪ¾ĪŻ
ļSų°ĮøØ·Ą─▓╗öÓ░lš╣Ż¼ėŗ╦ŃÖCŠWĮjĄ─▓╗öÓ╔ŅČ╚Ųš╝░Ż¼▓╗āHĮo╬ęéāĦüĒ┴╦║Ż┴┐Ą─öĄō■Ż¼═¼Ģr×ķŽĄĮyĄ─╔ŅČ╚░lš╣ĦüĒ┴╦╔·ÖCĪŻū„š▀šJ×ķ╬┤üĒĄ─ŽĄĮy░lš╣╩ŪöĄō■Ė³×ķęÄĘČ╗»Īó╚½Ū“╗»ĪóųŪ─▄╗»Īó├µŽ“ī”Ž¾╗»Ż¼ŠWĮjČÓ├Į¾w╝╝ągĪó┬ōÖCĘų╬÷╠Ä└ĒĄ╚ą┬┼d╝╝ągīó▓╗öÓ╚┌╚ļĪŻįŁ▌dĪČ╔Į¢|╗»╣żĪĘ2011Ż©9Ż®