ĪĪĪĪę╗Īóę² čį
Į±╠ņ�����Ż¼ėŗ╦ŃÖCŠW(w©Żng)Įj║═ą┼Žó╝╝ągĄ─čĖ├═░l(f©Ī)š╣┤¾┤¾Ąž═Ųäė┴╦╔ńĢ■Ą─░l(f©Ī)š╣���Ż¼╦³Ą─ė░Ēæ║═╦▌╝░┴”ęčĮø(j©®ng)▒ķ▓╝š¹éĆ╔ńĢ■Ą─ĘĮĘĮ├µ├µ�Ż¼▓óŪęį┌Ę©┬╔ŅIė“ųØu’@╩Š│÷ÅŖėą┴”Ą─ā×(y©Łu)ä▌����Ż¼¤ošō╩Ūī”╚š│ŻĄ─╦ŠĘ©śI(y©©)äš╠Ä└ĒŻ¼▀Ć╩ŪĘ©īW蹊┐┼c╦ŠĘ©▐k░ĖøQ▓▀Č╝┘xėĶ┴╦ą┬Ą─ĘĮĘ©║═╦╝┬ĘŻ¼įĮüĒįĮ░l(f©Ī)ō]ų°╦³Ą─▌oų·ų¦│ųū„ė├�ĪŻ
ĪĪĪĪ╚╗Č°├µī”ų°ŠW(w©Żng)ĮjųąįĮüĒįĮÕeŠCÅ═ļs��Īóļyęį├Ķ╩÷Ą──Ż║²å¢Ņ}║═║Ż┴┐ĘŪĮYśŗ╗»Ą─öĄ(sh©┤)ō■(j©┤)Ż¼╚ń║╬ØMūŃī”ŲõĖ▀ą¦Ą─▓ķįāšłŪ¾Ż¼ęįĖ³Ą═Ą─│╔▒Š���ĪóĖ³£╩┤_Ą─öĄ(sh©┤)ō■(j©┤)║═Ė³čĖĮ▌Ą─╦┘Č╚ū„│÷š²┤_Ą─øQ▓▀Ż¼╩Ū«öŪ░ą┼Žó½@╚Ī║═└¹ė├╦∙├µ┼RĄ─ĻPµIå¢Ņ}ĪŻ╦ŠĘ©øQ▓▀╚╦åTį┌▓ķįā─┐ś╦▓╗║▄├„┤_Ą─ĀŅørŽ┬▀xō±øQ▓▀ę└ō■(j©┤)ĢrŻ¼ūóųžĄ─╩Ū╚ń║╬Å─║Ų╚ń¤¤║ŻĄ─öĄ(sh©┤)ō■(j©┤)ųą┐ņ╦┘Ąžš{│÷┼c░Ė╝■ŽÓĻPĄ─Ę©┬╔ĪóĘ©ęÄ(gu©®)╝░┼ą└²���Ż¼Č°▓╗╩Ū▒ķÜv²ŗ┤¾Ą─╗ź┬ō(li©ón)ŠW(w©Żng)╗“öĄ(sh©┤)ō■(j©┤)Äņ┘Yį┤┬■¤o─┐ś╦Ąž╦čīżĪŻČ°─┐Ū░┤¾ČÓöĄ(sh©┤)ŠW(w©Żng)Įj╦č╦„ę²Ūµ║═ą┼Žó½@╚Ī╣żŠ▀╩Ū╗∙ė┌Öz╦„╠ßå¢╩ĮĻPµIį~Ųź┼õ╝╝ągŻ¼į┌Öz╦„Ą─▀^│╠ųą│Ż│Ż│÷¼F(xi©żn)Ą─ā╔ŅÉų„ę¬å¢Ņ}╩ŪĪ░ą┼Žó▀^▌dĪ▒║═Ī░ā╚╚▌▓╗Ųź┼õĪ▒�����ĪŻŪ░š▀ųĖį┌Öz╦„▀^│╠ųąŽĄĮy(t©»ng)ĘĄ╗žĄ─ą┼Žó┴┐▀^ČÓ����Ż¼┼c▓ķšęŽÓĻP╗“▓╗ŽÓĻPĄ─ā╚╚▌Č╝├░│÷üĒŻ¼╩╣ė├æ¶æ¬Įė▓╗ŽŠŻ¼ļyė┌Įė╩▄Ż╗║¾š▀ųĖę“ī”═¼ę╗éĆĖ┼─ŅĄ─▒Ē╩÷│÷¼F(xi©żn)ČÓ┴x�����ĪóŲń┴x��Ż¼ĘĄ╗žĄ─ą┼Žó▓óĘŪė├涚µīŹĄ─▓ķįāęŌłD║═ā╚╚▌���Ż¼▓ķ£╩┬╩║═▓ķ╚½┬╩Č╝Ą├▓╗ĄĮ▒ŻūC��ĪŻ
ĪĪĪĪę¬ĮŌøQŠW(w©Żng)ĮjŁh(hu©ón)Š│ųą╔Ž╩÷ą┼Žó½@╚Ī┤µį┌Ą─å¢Ņ}Ż¼īŹ¼F(xi©żn)šµš²ęŌ┴x╔ŽĄ─├µŽ“Ę©┬╔ŅIė“Ą─ų¬ūRÖz╦„�����Ż¼Å─└Ēšōīė├µ╔Ž�����Ż¼▒žĒÜśŗĮ©ęįĘ©┬╔ŅIė“ų¬ūR×ķ╗∙ĄAĄ─ė├ė┌šZ┴xÖz╦„Ą─į¬öĄ(sh©┤)ō■(j©┤)ś╦£╩Ż¼ė├üĒī”ŠW(w©Żng)ĒōųąĄ─ŽÓĻPą┼Žóś╦ę²║═ų¬ūR│ķ╚Ī���Ż¼ęį▒Ńīóė├æ¶▓ķįāšłŪ¾£╩┤_Ąž┼cŠW(w©Żng)Ēō╔Ž▓ķįāĄ─Ę©┬╔ų¬ūR─┐ś╦ŽÓŲź┼õŻ╗▀@Š═ę¬Ū¾╬ęéāī”üĒūįŠW(w©Żng)Ēō╗“öĄ(sh©┤)ō■(j©┤)ÄņĄ─Ę©┬╔ą┼Žó▀Mąąš¹└Ē���ĪóĮM┐Ś║═╠žš„Ęų╬÷Ż¼ę└ō■(j©┤)Ę©┬╔ŅIė“īŻ╝ę╦∙įOėŗĄ─Ę©┬╔ą┼ŽóęÄ(gu©®)ĘČś╦£╩���Ż¼Į©┴ó┐╔└¹ė├║═╣▓ŽĒĄ─Ę©┬╔ų¬ūRå╬į¬║═į¬öĄ(sh©┤)ō■(j©┤)Ż¼ęį▀_ĄĮųŪ─▄║═£╩┤_Ą─šZ┴xÖz╦„���Ż¼īŹ¼F(xi©żn)├µŽ“Ę©┬╔ŅIė“Ą─ų¬ūR½@╚ĪŻ¼×ķ╦ŠĘ©śI(y©©)äšą┼Žó╗»║═╦ŠĘ©øQ▓▀ą┼Žó╗»╠ß╣®Ė³╝ėėą┴”Ą─ų¦ō╬�ĪŻ
ĪĪĪĪČ■�����ĪóĘ©┬╔ą┼Žó┘Yį┤Ą─śŗ│╔┼cšZ┴x╠žš„Ęų╬÷
Ż©ę╗Ż®Ę©┬╔ą┼Žóų¬ūRå╬į¬Ą─ĮM┐Ś
ę╗░ŃüĒšf����Ż¼į┌Ę©┬╔╬─½IųąĄ─ų¬ūRā╚╚▌╩Ūė╔╚¶Ė╔éĆų¬ūRå╬į¬ĮM│╔���Ż¼ų¬ūRå╬į¬ų«ķgĄ─ĮYśŗĻPŽĄ╩ŪŽÓī”╣╠╗»Ą─���ĪŻė├æ¶į┌ŠW(w©Żng)╔Ž▓ķšęŲõųąĄ─ų¬ūRĢr�Ż¼ų╗─▄░┤ššŠÄš▀╩┬Ž╚ĮMČ©Ą─ŠĆąįĘĮ╩Įūx╚ĪŻ¼╝┤╩╣ų╗Žļ½@╚ĪŲõųą─│ę╗▓┐Ęų╩┬īŹ╗“öĄ(sh©┤)ō■(j©┤)Ż¼ę▓ę¬į┌½@╚Ī╚½╬─Ą─╗∙ĄA╔ŽĖ∙ō■(j©┤)ąĶę¬ųéĆ║Y▀xŻ¼▀@’@╚╗▓╗─▄ØMūŃė├æ¶Ą─īŹļHąĶŪ¾��ĪŻ╚ń╣¹─▄īó▀@ĘNŠĆąįĄ─ų¬ūRēK( ╬─½I) ĘųĮŌ×ķĖ„ĘN├µŽ“ė├æ¶å¢Ņ}ė“╗“╗∙ė┌╩┬īŹė“Ą─šJų¬īė┤╬Ą─╗Ņ╗»ų¬ūRå╬į¬��Ż¼▓óīó▀@ą®ų¬ūRå╬į¬ėĶęį╝ż╗ŅŻ¼ųžą┬ĮM║Ž���Īó┬ō(li©ón)ĮYĪó▐D╗»×ķ╠žČ©Łh(hu©ón)Š│�����Īó╠žČ©ąĶꬥ─ų¬ūR���Ż¼īó┤¾┤¾╠ßĖ▀Ę©┬╔╬─½Ių¬ūRĄ─└¹ė├┬╩┼c╣▓ŽĒąį��ĪŻę“┤╦���Ż¼ī”ė┌ŠW(w©Żng)ĒōųąĘ©┬╔╬─½I┘Yį┤╝░Ųõų¬ūRā╚╚▌▀Mąąėąą¦Ą─╠ߤÆ��Īóš¹ą“║═ų¬ūRå╬į¬Ą─ĮM┐ŚŻ¼▀MČ°ī”ŲõĘų╬÷║═╠žš„ś╦ę²���Ż¼īŹ¼F(xi©żn)░┤ė├æ¶å¢Ņ}ė“Ą─šZ┴xÖz╦„Ż¼Š═│╔×ķŠW(w©Żng)ĮjŁh(hu©ón)Š│ųąĘ©┬╔ų¬ūR½@╚ĪĄ─ĻPµI����ĪŻ
ĪĪĪĪ═©│ŻĄ─Ę©┬╔ą┼Žóų„ę¬░³└©Ż║Ę©┬╔╣½╬─Ż©║¼╦ŠĘ©╬─Ģ°Ż®�����Īó╬─½IŻ¼Ę©┬╔�ĪóĘ©ęÄ(gu©®)����Īó╦ŠĘ©ĮŌßī�Ż¼╦ŠĘ©░Ė└²Īó┼ą└²�Ż¼╦ŠĘ©ūCō■(j©┤)ęį╝░ŽÓĻPĄ─┬Ģę¶����ĪóęĢŅl�����ĪółDŽ±Ą╚ČÓ├Į¾w┘Y┴ŽĪŻ░┤šš╦ŠĘ©ŅIė“æTė├äØĘųŻ¼┐╔ęįīóĘ©┬╔ą┼ŽóĖ∙ō■(j©┤)Ųõąį┘|Īóū„ė├╗“╦∙ī┘▓┐ķTĘ©ŽĄ▀Mąąų¬ūRīė┤╬║═ų¬ūRå╬į¬Ą─ĮM┐ŚŻ║
ĪĪĪĪĄ┌ę╗īė��Ż¼╩Ūī”Ę©┬╔ą┼Žó╣½╣▓┘Yį┤▀Mąąę╗░Ńąį����ĪóĖ┼└©ąįĄ─├Ķ╩÷Ż¼═©│Ż▀mė├ė┌├Ķ╩÷╣®ÜwÖnĄ─Ę©┬╔╣½╬─Ż©Ę©┬╔╬─╝■ĪóĘ©┬╔Ę©ęÄ(gu©®)��Īó╦ŠĘ©╬─Ģ°Ą╚Ż®ą┼Žó��Ż¼ė╔ę╗ĮM│ķŽ¾│÷üĒĄ─īŻśI(y©©)ągšZ▒Ēš„�Ż¼╗∙▒Š╔Ž┐╔ęį┴_┴ą│÷╚ńŽ┬╚¶Ė╔ĒŚŻ║░l(f©Ī)╬─ŠÄ╠¢�����Īó░l(f©Ī)╬─ÖCśŗ��Īó╬─╝■├¹ĘQĪóų„Ņ}Īóš¬ę¬����Īó░l(f©Ī)▓╝╚šŲ┌�����Īó░l(f©Ī)▓╝ĘČć·�Īó╩╣ė├šZčį���Īó╩┬╝■����ĪóĻP┬ō(li©ón)���Īó├▄╝ē��Īóėąą¦ąįĄ╚Ż©┐╔ė├Ī░į¬öĄ(sh©┤)ō■(j©┤)Ī▒├Ķ╩÷Ż®����ĪŻ
ĪĪĪĪĄ┌Č■īė�����Ż¼┐╔ęįÅ─Ę©┬╔ą┼ŽóĄ─æ¬ė├ĮŪČ╚Ż©ąį┘|╗“▀mė├ŅIė“Ą╚Ż®����Ż¼ī”Ę©┬╔ą┼ŽóĄ─ų¬ūRå╬į¬▀MąąĮM┐Ś║═├Ķ╩÷����Ż¼└²╚ńŻ¼░č╦³éāĘų×ķą╠╩┬ŅÉĪó├±╩┬ŅÉ����Īóąąš■ŅÉ�Īó║Ż╩┬ŅÉ�Ż╗╗“š▀Ęų×ķŲįVŅÉĪó┼ąøQŅÉĪó║Ž═¼ŅÉ��Īó╣½ĖµŅÉ��Ż╗▀Ć┐╔ęį░č╦³éāĘų×ķŻ║Ę©┬╔����ĪóĘ©ęÄ(gu©®)┼c┼ą└²�����Īó░Ė└²Ż╗ą╬│╔ßśī”▓╗═¼å¢Ņ}ė“║═Öz╦„─┐ś╦Ą─ų¬ūRŠS�����ĪŻ
ĪĪĪĪĄ┌╚²īė���Ż¼ätę└ō■(j©┤)Š▀¾wą┼Žóā╚╚▌▀MąąĖ┼─ŅĄ─│ķŽ¾║═├Ķ╩÷�Ż¼═©│Ż┐╔ęįßśī”Ę©┬╔╣½╬─Ą─ų„Ņ}����Īóā╚╚▌š¬ę¬ęį╝░├Ķ╩÷Š▀¾w░Ė╝■����Īó╩┬īŹĄ─ą┼ŽóŻ©═∙═∙ė├╚¶Ė╔éĆĻPµIį~├Ķ╩÷Ż®����Ż¼└²╚ńŻ¼ū’├¹�����Īó╩┬ė╔╗“░ĖŪķ║åĮķ�Ż¼▓óČ©┴xŲõŽ┬ī┘Ė┼─ŅĪóā╚╚▌║═ŽÓĻPĄ─ī┘ąį╝░ĻPŽĄ��Ż¼ėų╚ń����Ż¼░ĖŪķš¬ę¬ųąĄ─ų„ę¬ĻPµIį~���Ż¼įŁĖµĪó▒╗Ėµ���Īó▒╗║”╚╦╝░Ųõąš├¹Īóąįäe����Īó─Ļ²g���Īó╔ĒĘ▌����Īó╠žš„Ą╚���ĪŻ═©│ŻĄ┌╚²īėą┼Žó▌^┴Ń╔ó����Īó─Ż║²Īó▓╗ęÄ(gu©®)ĘČ�����Īóļyęį├Ķ╩÷���Ż¼└²╚ńŻ║░ĖŪķš¬ę¬ųąĄ─ĘĖū’äėÖC����Īóįņ│╔Ą─╬Ż║”╝░║¾╣¹Ą╚ĪŻÜw╝{ŲüĒ�����Ż¼├µŽ“░Ė╝■╩┬īŹĄ─Ę©┬╔╣½╬─░³║¼Ą─ų¬ūRų„ę¬ėąŻ║
ĪĪĪĪ(1) Ę©┬╔╬─½Ią┼Žó��ĪŻėøõø▓╗═¼ė├═ŠĄ─╦ŠĘ©╬─½IĄ─╗∙▒Šą┼ŽóŻ¼└²╚ńŻ¼░l(f©Ī)╬─ŠÄ╠¢Īó░l(f©Ī)╬─ÖCśŗĪóŠÄųŲš▀���Īó╬─╝■├¹ĘQĪó╬─╝■ŅÉäeĪóų„Ņ}���Īóš¬ę¬Īó░l(f©Ī)▓╝╚šŲ┌Īó░l(f©Ī)▓╝ĘČć·�����Ż¼╩╣ė├šZčį���Īó╩┬╝■��Īó╩┬╝■ĻP┬ō(li©ón)�����Īó╗∙▒ŠĖ±╩ĮĄ╚ĪŻ
ĪĪĪĪ(2) ÖCśŗ╗“éĆ╚╦ą┼ŽóĪŻėøõø┼c░Ė╝■╩┬īŹŽÓĻPĄ─╦ŠĘ©ÖCśŗ���ĪóĘ©╚╦Īó▒╗ĖµĪóįŁĖµĪó▒╗║”╚╦Ą╚Ą─╗∙▒Šą┼Žó�����Ż¼└²╚ń��Ż¼Ę©╚╦Ą─ąš├¹�����ĪóąįäeĪó─Ļ²gĪó┬ÜäšĪóå╬╬╗�ĪóĄžųĘĄ╚ĪŻ
ĪĪĪĪ(3) ╩┬╝■ą┼Žó��ĪŻėøõø╦ŠĘ©╩┬īŹ░l(f©Ī)╔·Ą─įö╝ÜĮø(j©®ng)▀^ą┼Žó����Ż¼└²╚ń�����Ż¼╩┬╝■░l(f©Ī)╔·ĢrķgĪóĄž³cŻ¼ŽÓĻPš▀���Īó╩┬╝■║¾╣¹╝░ĮYšōĄ╚ĪŻ
ĪĪĪĪ(4) ĘĖū’ą┼ŽóĪŻėøõøū’ąąĄ─╗∙▒Šą┼ŽóŻ¼└²╚ń����Ż¼ū’├¹�ĪóĘĖū’╚╦����Īó▒╗║”╚╦ĪóäėÖCĪóŪķ╣Ø(ji©”)����ĪóįŁę“����Īó╬Ż║”║¾╣¹�Īó╠Ä┴PŪķørĄ╚Ż╗▀Mę╗▓Įīó▀@ą®│ķŽ¾│÷üĒĄ─Ė┼─Ņš¹└Ē�����Ż¼šę│÷╦³éāų«ķgĄ─▀ē▌ŗĻPŽĄ��ĪŻęįĘ©┬╔╣½╬─Ą─┼ąøQĢ°×ķ└²Ż¼Å─Ą┌ę╗īė╦∙├Ķ╩÷Ą─╦ŠĘ©╬─Ģ°Ą─├¹ĘQ����Īóų„Ņ}����Īóš¬ę¬ųą┐╔ęį│ķ│÷Ž┬īėėąĻPū’ąą��ĪóĘĖū’ąį┘|║═ĘĖū’╩┬īŹą┼Žó�Ż¼į┘▀Mę╗▓ĮīżĖ∙╦„¾K�Ż¼š{│÷ĘĖū’╚╦ĪóĘĖū’äėÖC�����Īóū„░ĖĮø(j©®ng)▀^�����ĪóĘĖū’║¾╣¹ęį╝░┼ąøQĮY╣¹Ą╚įö╝Üšf├„ą┼Žó����Ż¼▀@ą®ėųų▒Įė┼cū’ąąŽÓ▀mæ¬Ą─Ę©┬╔Śl╬─║═┼ą└²ŽÓĻP┬ō(li©ón)�ĪŻė╔┤╦Ż¼Š═ą╬│╔┴╦ę╗éĆę└ō■(j©┤)├Ķ╩÷Ę©┬╔╩┬īŹĄ─╦ŠĘ©╬─Ģ°Č°┤ŅĮ©Ą─šZ┴xĻPŽĄŠW(w©Żng)ĮjŻ©╚ńłD1 ╦∙╩ŠŻ®
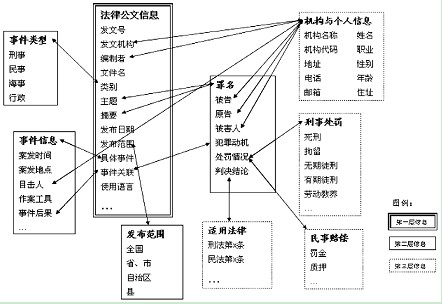
łD1 Ę©┬╔ą┼ŽóĄ─šZ┴xĻPŽĄŠW(w©Żng)ĮjłD
Ż©Č■Ż®Ę©┬╔╣½╬─Ą─šZ┴x╠žš„─┐Ū░�Ż¼ļSų°╦ŠĘ©ŅIė“ą┼Žó╗»���ĪóöĄ(sh©┤)ūų╗»Ą─═Ų▀M���Ż¼ć°ā╚╦ŠĘ©Įńęčī”Ė„ŅÉĘ©┬╔ą┼Žó▀Mąą┴╦▌^╝Üų┬Ą─äØĘų��Ż¼▓óųŲėå┴╦Įy(t©»ng)ę╗ĪóęÄ(gu©®)ĘČĄ─Ė±╩Į�Ż¼ą╬│╔┴╦ś╦£╩ĘČ▒ŠŻ©┐╔ģó┐╝ūŅĖ▀╚╦├±Ę©į║��ĪóūŅĖ▀╚╦├±Öz▓ņį║░l(f©Ī)▓╝Ą─Ę©┬╔╣½╬─Ė±╩ĮĪóęÄ(gu©®)Ė±Ģ°Ą╚Ż®�����Ż¼▀@×ķŠW(w©Żng)Ēō╔ŽĘ©┬╔ą┼Žóų¬ūRå╬į¬Ą─ĮM┐Ś║═Ę©┬╔ų¬ūRĄ─│ķ╚Ī�����Ż¼▀MČ°śŗĮ©Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)┤ŅĮ©┴╦┴╝║├Ą─╗∙ĄAŲĮ┼_ĪŻ└²╚ńŻ¼╬ęéā┐╔ęįė├Ę┤ė│Ę©┬╔░Ė╝■�����Īó╩┬īŹĄ─╦ŠĘ©╬─Ģ°Ż©ŲįVĢ°Īó┼ąøQĢ°����Īó║Ž═¼Ą╚Ż®ū„×ķĘų╬÷ī”Ž¾����Ż¼├Ķ╩÷╦³Ą─╗∙▒ŠĖ±╩Į�����Ż¼│ķ╚ĪĖ„▓┐ĘųĄ─ĻPµIį~╝░ŲõšZ┴x╠žš„����Ż¼░┤šš▀@ą®ĻPµIį~į┌ŠW(w©Żng)Ēō╬─ÖnųąĖ„▓┐Ęų│÷¼F(xi©żn)Ą─Ņl┬╩�����Īó╬╗ų├ĻPŽĄ║═ÖÓųž▀Mąąś╦ę²�Ż¼Öz╦„│÷Ųõį┌ŽÓĻPŠW(w©Żng)Ēō╔ŽĄ─Ę©┬╔�����ĪóĘ©ęÄ(gu©®)Īó░Ė└²║═┼ą└²ĪŻ
ĪĪĪĪŠW(w©Żng)Ēō░l(f©Ī)▓╝ūŅŲš▒ķĄ─Ę©┬╔ą┼ŽóČÓ×ķ╬─▒Šą╬╩Į����Ż¼Č°ęįĘ©┬╔╩┬īŹ����Īó░Ė└²×ķų„ŠĆĄ─Ę©┬╔╬─▒Šätų„ę¬×ķĘ©┬╔╣½╬─���Ż¼╦∙ęį���Ż¼▒ŠčąŠ┐ųž³c╩Ūī”Ę┤ė│Ę©┬╔╩┬īŹ░Ė└²Ą─Ę©┬╔╣½╬─▀MąąĘų╬÷║═ėæšō���ĪŻ
ĪĪĪĪ▒M╣▄Ė„ŅÉĘ©┬╔╣½╬─Ą─ā╚╚▌▓╗ę╗���Ż¼Ą½╦³éāĄ─╗∙▒Šą╬╩Į╩ŪŽÓ╦ŲĄ─����Ż¼┼cŲõ╦¹╬─ÖnŽÓ▒╚Š▀ėą’@├„Ą─Ė±╩ĮĪŻ
ĪĪĪĪė╔┤╦����Ż¼┐╔ęįīóŠW(w©Żng)ĮjŁh(hu©ón)Š│ųąĘŪĮYśŗ╗»Ą─Ę©┬╔ą┼Žó▐D╗»×ķ▌^ęÄ(gu©®)ĘČĄ─ĮYśŗ╗»Ą─öĄ(sh©┤)ō■(j©┤)Ė±╩Į����Ż¼▀MČ°�����Ż¼śŗĮ©│÷ė├üĒīŹ¼F(xi©żn)šZ┴xÖz╦„Ą─Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)╝░Ųõ┐╔ś╦ę²ĪóĘųŅÉĄ─ų„Ņ}ĻPŽĄį~▒ĒĄ─┤¾ų┬┐“╝▄�����ĪŻ
ĪĪĪĪ╚²����ĪóĘ©┬╔ą┼ŽóšZ┴xÖz╦„Ą─śŗ╝▄
(ę╗Ż®Ę©┬╔ų„Ņ}ĻPŽĄį~▒ĒĄ─įOėŗ
░┤ššŪ░╩÷ų¬ūRĮM┐Ś¾wŽĄĄ─äØĘųŻ¼ų„Ņ}ĻPŽĄį~▒Ēį┌ŅIė“ų¬ūRå╬į¬ųą░ńč▌ų°śOŲõųžę¬Ą─ĮŪ╔½���Ż¼╩Ūę╗ĘNų„Ņ}Öz╦„ŽĄĮy(t©»ng)╦∙ė├Ą─Öz╦„į~Ą─ėąą“╗»į~ģR▒ĒŻ¼─▄ē“▒Ē▀_ūį╚╗šZčįų«ķgšZ┴xĻPŽĄĄ─��Īóėąś╦ę²║═╠ß╣®Ė„ĘN▓ķįā═ŠÅĮĄ─į~╗“į~ĮM��ĪŻū„×ķę╗ĘNīóŠW(w©Żng)Įj┘Yį┤║═ą┼Žóė├æ¶Ą─ūį╚╗šZčį▐DōQ×ķęÄ(gu©®)ĘČ╗»šZčįĄ─╣żŠ▀����Ż¼ų„Ņ}ĻPŽĄį~▒Ēį┌╬─½Iś╦ę²║═ą┼ŽóÖz╦„Ą╚ĘĮ├µŠ▀ėąÅVĘ║Ą─æ¬ė├ĪŻ
ĪĪĪĪ×ķ┴╦īŹ¼F(xi©żn)▒Š╬─╦∙╠ß│÷Ą─╗∙ė┌Ę©┬╔▒Š¾wĄ─šZ┴xÖz╦„ęŌłD����Ż¼╬ęéāę└ō■(j©┤)ūŅĖ▀╚╦├±Ę©į║░l(f©Ī)▓╝Ą─Ī░╚╦├±Ę©į║╣½╬─ų„Ņ}į~▒ĒĪ▒Ī▓1Ī│�Ż¼ī”▓┐Ęųų„Ņ}į~▀Mąą┴╦ĘųŅÉŠÄ┤a��Ż¼▓óģóššųąć°┐ŲīW╝╝ągą┼Žó蹊┐╦∙ŠÄųŲĄ─Ī░ŠC║ŽļŖūėš■äšų„Ņ}į~▒ĒŻ©įćė├▒ŠŻ®Ī▒Ī▓2Ī│����Ż¼įOėŗ┴╦ę╗╠ūė├ė┌▒ŠčąŠ┐Öz╦„įŁą═ŽĄĮy(t©»ng)Ą─Ę©┬╔ą┼Žóų„Ņ}ĻPŽĄį~▒Ē▓ķįā─Ż░ÕŻ©ęŖ▒Ē1Ż®Ż║
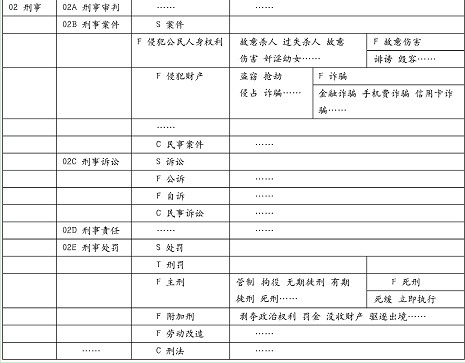
ĪĪĪĪĘ©┬╔ą┼Žóų„Ņ}ĻPŽĄį~▒ĒŻ©śė└²Ż®į┌─Ż░Õųą���Ż¼ų„Ņ}ĻPŽĄį~▒Ēūįū¾ų┴ėę¾w¼F(xi©żn)┴╦ų„Ņ}Ė┼─ŅĄ─śõą╬īė┤╬ĮYśŗ�����ĪŻĄ┌ę╗┴ą▒Ē╩Šų„Ņ}į~Ą─╦∙ī┘ĘČ«ĀŻ¼└²╚ń�Ż¼Ī░ą╠╩┬Ī▒���ĪóĪ░├±╩┬Ī▒Ą┌Č■┴ą×ķÜwŅÉė┌ū¾┴ąĘČ«ĀŽ┬Ą─ų„Ņ}į~��Ż¼└²╚ńŻ¼Ī░ą╠╩┬ž¤╚╬Ī▒ī┘ė┌Ī░ą╠╩┬Ī▒ĘČ«Ā���ĪŻĄ┌╚²┴ą×ķ┼cū¾┴ąų„Ņ}į~ŽÓĻPĄ─Ė┼─ŅŻ¼S-Ż©ī┘Ż®ĒŚ����Ż¼▒Ē╩Šįōį~Ą─╔Ž╬╗Ė┼─Ņ��Ż╗F-Ż©ĘųŻ®ĒŚŻ¼▒Ē╩Šįōį~Ą─Ž┬╬╗Ė┼─Ņ�����Ż╗C-Ż©ģóŻ®ĒŚ���Ż¼▒Ē╩Šįōį~Ą─ģó┐╝Ė┼─Ņ�Ż╗T-Ż©═¼Ż®ĒŚŻ¼▒Ē╩Šįōį~Ą─═¼┴xį~�����ĪŻĄ┌╦─┴ą×ķū¾┴ą░³║¼Ą─Ė┼─ŅŻ©╠žš„į~Ż®��Ż¼├┐ę╗Ė┼─ŅŽ┬ėų┐╔└^└m(x©┤)Ž┬ĘųŠ▀¾wā╚╚▌Ż©╚ńĄ┌╬Õ┴ąŻ®�ĪŻ└²╚ń��Ż¼Ī░ą╠╩┬╠Ä┴PĪ▒ ī┘Ī░ą╠╩┬Ī▒ĘČ«Ā����Ż¼╦³Ą─╔ŽīėŅÉī┘Ż©╔Ž╬╗į~Ż®╩ŪĪ░╠Ä┴PĪ▒�Ż¼╦³Ą─Ž┬īėĘųŅÉŻ©Ž┬╬╗į~Ż®╩ŪĪ░ų„ą╠Ī▒�ĪóĪ░ĖĮ╝ėą╠Ī▒ĪóĪ░ä┌äėĖ─įņĪ▒Ż¼╦³Ą─ģó┐╝Ė┼─Ņ╩ŪĪ░ą╠Ę©Ī▒Ż¼╦³Ą─═¼┴xį~╩ŪĪ░ą╠┴PĪ▒Ż╗Č°į┌ŲõŽ┬īėĖ┼─Ņųąėų░³║¼┴╦Ė³Ž┬īėŻ©Ž┬╬╗Ż®Ą─Ė┼─Ņ�Ż¼└²╚ń�Ż¼Ī░ą╠╩┬╠Ä┴PĪ▒Ą─Ī░ų„ą╠Ī▒ųą┐╔░³║¼Ī░╣▄ųŲĪ▒�ĪóĪ░Šąę█Ī▒ĪóĪ░¤oŲ┌═Įą╠Ī▒ĪóĪ░ėąŲ┌═Įą╠Ī▒���ĪóĪ░╦└ą╠Ī▒Ą╚▒Ē╩ŠŽÓĻPĖ┼─ŅĄ─╠žš„į~Ż¼Ī░╦└ą╠Ī▒ųąĖ³Š▀¾wĄ─╩ŪĪ░┴ó╝┤ł╠(zh©¬)ąąĪ▒║═Ī░╦└ŠÅĪ▒ĪŻ
ĪĪĪ��ĪŻ©Č■Ż®Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)Ą─įOėŗį¬öĄ(sh©┤)ō■(j©┤)▒╗šJ×ķ╩Ūę╗ĘNė├üĒ├Ķ╩÷öĄ(sh©┤)ūų╗»ą┼Žó┘Yį┤��Ż¼╠žäe╩ŪŠW(w©Żng)Įją┼Žó┘Yį┤Ą─╗∙▒Š╠žš„╝░ŲõŽÓ╗źĻPŽĄ�����Ż¼Å─Č°┤_▒Ż▀@ą®öĄ(sh©┤)ūų╗»ą┼Žó┘Yį┤─▄ē“▒╗ėŗ╦ŃÖC╝░ŲõŠW(w©Żng)ĮjŽĄĮy(t©»ng)ūįäė▒µūRĪóĘųĮŌŠ█ŅÉ║═Ęų╬÷Üw╝{( ╝┤╦∙ų^ÖCŲ„┐╔└ĒĮŌąį) Ą─ę╗š¹╠ūŠÄ┤a¾wŽĄŻ¼╦³┤·▒Ēę╗ĮM▒╗ÅVĘ║šJ═¼Ą─Īó─▄£╩┤_├Ķ╩÷ą┼Žó┘Yį┤ī┘ąį║═ŅIė“╠ž³cĄ─ūŅ╗∙▒ŠĄ─į¬╦žŻ¼╦³═©▀^ī”ŠW(w©Żng)Įj┘Yį┤öĄ(sh©┤)ō■(j©┤)Ą─ĮYśŗĪóā╚╚▌ĪóĻPŽĄ�����ĪóŚl╝■║═Ųõ╦¹╠žš„▀Mąą├Ķ╩÷┼cšf├„�����Ż¼Ä═ų·╚╦éāėąą¦ĄžČ©╬╗���ĪóĮM┐Ś�Īó╠ß╚ĪĪóĘų╬÷║═╩╣ė├ŠW(w©Żng)Įj┘Yį┤öĄ(sh©┤)ō■(j©┤)�����ĪŻć°ļHłD┬ō(li©ón)IFLA ī”į¬öĄ(sh©┤)ō■(j©┤)Ą─Č©┴x╩ŪŻ║Ī░į¬öĄ(sh©┤)ō■(j©┤)Š═╩ŪĻPė┌öĄ(sh©┤)ō■(j©┤)Ą─öĄ(sh©┤)ō■(j©┤)Ż©data about dataŻ®���Ż¼┤╦ągšZųĖ╚╬║╬ė├ė┌Ä═ų·ŠW(w©Żng)Įj┘Yį┤Ą─ūRäe���Īó├Ķ╩÷║═Č©╬╗Ą─öĄ(sh©┤)ō■(j©┤)�����ĪŻĪ▒Ī▓3Ī│╣½╣▓┘Yį┤╗∙▒Šį¬öĄ(sh©┤)ō■(j©┤)æ¬─▄ē“▒Ē╩÷╚ńŽ┬Ą─ą┼ŽóŻ║┘Yį┤├¹ĘQĪó┘Yį┤ų„Ņ}���Īó┘Yį┤ś╦ūRĪó┘Yį┤š¬ę¬Īó┘Yį┤Ė±╩Įą┼Žó���ĪóĻPµIūųšf├„Īó┐šķgĘČć·�ĪóĢrķgĘČć·����Īó┘Yį┤╩╣ė├Ž▐ųŲ�Īó┘Yį┤šZĘNĪó┘Yį┤ŅÉą═Īó┘Yį┤ś╦ūRĘ¹����Īóį┌ŠĆ┘Yį┤µ£ĮėĄžųĘĄ╚ą┼Žó�����ĪŻ
ĪĪĪĪ═©▀^ī”ć°ā╚═Ōį¬öĄ(sh©┤)ō■(j©┤)ś╦£╩Ą─蹊┐║═╠Į╦„Ż¼▒ŠčąŠ┐ę└ō■(j©┤)ć°ļH═©ė├Ą─į¬öĄ(sh©┤)ō■(j©┤)įOėŗįŁät║═Ę©┬╔╣½╬─Ą─Ė±╩Į║═šZ┴x╠žš„Ż¼▓óģóššć°╝ęļŖūėš■äšś╦£╩╗»ĒŚ─┐╣żū„ĮMĄ─ĪČš■äšą┼Žó┘Yį┤─┐õø¾wŽĄĪĘĄ─ę¬Ū¾┼cŲõ╦¹īŻśI(y©©)æ¬ė├ŅIė“į¬öĄ(sh©┤)ō■(j©┤)Ą─ŠÄųŲĘĮĘ©Ż¼į┌Č╝░ž┴ųDC į¬öĄ(sh©┤)ō■(j©┤)Ą─║╦ą─į¬╦ž╝»Ī▓4Ī│Ą─╗∙ĄA╔Žū„┴╦ę╗Č©Ą─öU│õ�Īóäh£p║═ą▐Ė─�Ż¼įOėŗ┴╦ę╗╠ū╝╚─▄¾w¼F(xi©żn)ć°ļH═©ė├ś╦£╩��Īóėų─▄Ę┤ė│Ę©┬╔╣½╬─╠ž³cĄ─Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)─Żą═�Ż¼═¼Ģr�Ż¼▒Ż┴¶┴╦DC ųąĄ─Ž▐ųŲī┘ąįÄ═ų·└ĒĮŌĖ„į¬╦ž╚ĪųĄĄ─║¼┴xĪŻŲõųą║╦ą─į¬╦ž╝»░³║¼┴╦14 éĆ╗∙▒Šį¬╦žŻ║ś╦Ņ}Īóäō(chu©żng)Į©š▀�Īóų„Ņ}����Īóš¬ę¬�����Īó░l(f©Ī)▓╝š▀ĪóŅÉą═�ĪóĖ±╩Į�����Īóś╦ūRĘ¹ĪóüĒį┤����ĪóšZĘN��ĪóĻP┬ō(li©ón)Īó╚šŲ┌���ĪóĖ▓╔wĘČć·ĪóÖÓŽ▐����ĪŻ┴Ē═Ō����Ż¼×ķ┴╦─▄Ė³║├Ąž¾w¼F(xi©żn)Ę©┬╔ą┼ŽóĄ─╠ž³c��Ż¼╬ęéāģóšš┴╦▓┐Ęų╠ž╩Ōæ¬ė├ŅIė“į¬öĄ(sh©┤)ō■(j©┤)ś╦£╩�����Ż¼╚ńĪ░ų„Ņ}ą┼ŽóĘ■䚯©ROADSŻ®Ī▒��ĪóĪ░š■Ė«ą┼ŽóČ©╬╗Ę■䚯©GILSŻ®Ī▒║═Ī░Į╠ė²ī”Ž¾į¬öĄ(sh©┤)ō■(j©┤)IEEE LOMĪ▒Ż¼ī”Č╝░ž┴ųDC į¬öĄ(sh©┤)ō■(j©┤)Ą─╗∙▒Šį¬╦ž▀Mąą┴╦öUš╣║═ča│õ���ĪŻ└²╚ń�Ż¼┘Yį┤├▄╝ē, ╩┬╝■, ╩┬╝■ŽÓĻPš▀Ż©▒╗Ėµ╚╦ĪóŲįV╚╦���Īó▒╗║”╚╦ĪóūC╚╦�Īó┤·└Ē╚╦Ą╚Ż®�����Ż¼īÅ┼ąÖCśŗŻ¼ų„Ņ}į~▒ĒĄ╚����Ż¼▓óįOėŗ┴╦Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)öUš╣į¬╦ž╝»��ĪŻŽ┬├µ▒Ē2Īó▒Ē3 Įo│÷┴╦▀@╠ūį¬öĄ(sh©┤)ō■(j©┤)ųą╚¶Ė╔į¬╦ž╝░ŲõČ©┴xĄ─╗∙▒Šśė└²�����ĪŻ
ĪĪĪĪ▒Ē2 Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)╗∙▒Šį¬╦ž╝»Ż©śė└²Ż®┬į
▒Ē3 Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)öUš╣į¬╦ž╝»Ż©śė└²Ż®
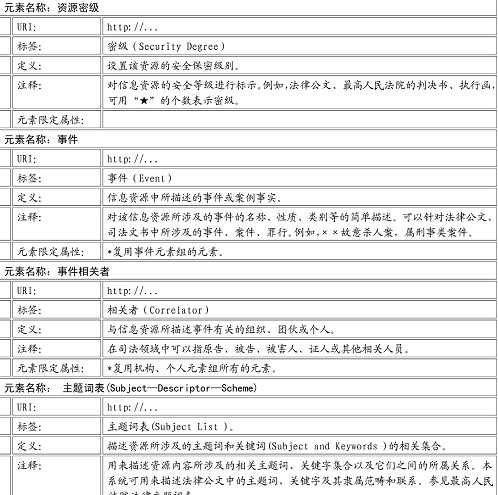
Ž┬├µ╩Ūģó┐╝Ī░ROADS ─Ż░µĪ▒Ī▓5Ī│įOėŗĄ─ÖCśŗ�ĪóéĆ╚╦Īó╩┬╝■į¬╦žĮM��Ż¼┐╔ęįĖ∙ō■(j©┤)īŹļHąĶę¬Å═ė├����ĪŻ
ĪĪĪĪŻ©1Ż®éĆ╚╦į¬╦žĮM�����ĪŻ
ĪĪĪĪś╦ūRĘ¹Ż©IdŻ®�����Īóąš├¹Ż©NameŻ®Ż¼▓┐ķTŻ©DepŻ®Ż¼┬Ü䚯©Job-TitleŻ®���Ż¼ĄžųĘŻ©AddressŻ®Ż¼ļŖįÆŻ©PhoneŻ®Ż¼Ó]š■ĄžųĘŻ©PostalŻ®�Ż¼ļŖūėÓ]╝■Ż©EmailŻ®��ĪŻ
ĪĪĪĪŻ©2Ż®ÖCśŗį¬╦žĮMĪŻ
ĪĪĪĪś╦ūRĘ¹Ż©IdŻ®Īó├¹ĘQŻ©NameŻ®���Ż¼ÖCśŗŅÉą═Ż©Og-TypeŻ®Ż¼╦∙ī┘╩ĪĪó╩ąĪóģ^(q©▒)Ż©ZoneŻ®���Ż¼ĄžųĘŻ©AddressŻ®Ż¼ļŖįÆŻ©PhoneŻ®Ż¼Ó]š■ĄžųĘŻ©PostalŻ®��Ż¼ļŖūėÓ]╝■Ż©EmailŻ®����Ż¼é„šµŻ©FaxŻ®ĪŻ
ĪĪĪĪŻ©3Ż®╩┬╝■į¬╦žĮM����ĪŻ
ĪĪĪĪś╦ūRĘ¹Ż©IdŻ®�Īó├¹ĘQŻ©NameŻ®����Ż¼ŅÉą═Ż©TypeŻ®Ż¼ąį┘|Ż©FibreŻ®Ż¼╚╦╬’(Person)Ż¼įŁę“Ż©CauseŻ®���Ż¼ĢrķgŻ©TimeŻ®Ż¼Ąž³cŻ©PlaceŻ®Ż¼ĮY╣¹Ż©ResuleŻ®����ĪŻ
ĪĪĪĪ╦─��ĪóĘ©┬╔ą┼ŽóšZ┴xÖz╦„ĘĮĘ©
Ż©ę╗Ż®Ę©┬╔ą┼ŽóšZ┴xÖz╦„Ą─╠ž³c╦∙
ų^ą┼ŽóÖz╦„Ż©Information RetrievalŻ®Ż¼╩ŪųĖÅ─┤¾┴┐Ą─ą┼Žó┘Yį┤ųą▓ķšę│÷┼c╩╣ė├š▀ąĶŪ¾ŽÓĻPĄ─ā╚╚▌�����ĪŻ─┐Ū░Ą─ą┼ŽóÖz╦„╝╝ąg┤¾ų┬Ęų×ķ╚²ŅÉŻ║ ╚½╬─Öz╦„Ż©Text RetrievalŻ®��ĪóöĄ(sh©┤)ō■(j©┤)Öz╦„Ż©DataRetrievalŻ®║═ų¬ūRÖz╦„Ż©Knowledge RetrievalŻ®��ĪŻ╚½╬─Öz╦„║═öĄ(sh©┤)ō■(j©┤)Öz╦„Å─▒Š┘|╔ŽšfČ╝ī┘ė┌ĻPµIūųŲź┼õĄ─Öz╦„╝╝ągŻ¼▀@ĘN╗∙ė┌ĻPµIūųŲź┼õ╗“╩Ū╗∙ė┌īW┐ŲĘųŅÉĄ─Öz╦„╣żŠ▀ų«╦∙ęį▓╗─▄┴Ņ╚╦ØMęŌŻ¼ūŅų„ꬥ─įŁę“ų«ę╗Š═╩Ū╦³éā¤oĘ©═┌Š“Ė┼─Ņų«ķgĄ─ā╚į┌┬ō(li©ón)ŽĄ���Ż¼╦č╦„│÷Ė³╔ŅīėĄ─║¼┴xŻ¼į┌▓ķ╚½┬╩║═▓ķ£╩┬╩ĘĮ├µČ╝ėąę╗Č©Ą─ŠųŽ▐ąįĪŻČ°╗∙ė┌šZ┴xų¬ūRŲź┼õ╝╝ągĄ─ų¬ūRÖz╦„Ż¼īóé„Įy(t©»ng)╗∙ė┌ĻPµIūųĄ─Ųź┼õ╝╝ąg╔Ž╔²×ķ╗∙ė┌Ė┼─Ņ╣Ø(ji©”)³cĄ─ų¬ūRŲź┼õ�Ż¼į÷ÅŖ┴╦Öz╦„Ą─šZ┴xūRäe─▄┴”�����Ż¼Ųõ╠ž³c▒Ē¼F(xi©żn)į┌Ż║
ĪĪĪĪŻ©1Ż®Ž¹│²ūį╚╗šZčį└ĒĮŌųąĄ─Ųń┴xŻ¼├„┤_Ė┼─Ņ╦∙ī┘ĘČ«Ā║═║Ł┴x����Ż¼╠ßĖ▀ą┼ŽóÖz╦„Ą─▓ķ£╩┬╩�ĪŻ
ĪĪĪ���ĪŻ©2Ż®į┌šZ┴xś╦ę²Ą─╗∙ĄA╔Ž▀MąąšZ┴x═Ų└Ē����Ż¼└¹ė├╬─½IĄ─šZ┴xś╦ūó║═Ė┼─Ņ╝»Ą─šZ┴xĻPŽĄ╝░═Ų└ĒęÄ(gu©®)ätŻ¼Å─Č°═┌Š“│÷ŽÓĻP╗“ļ[║¼ą┼Žó�Ż¼īŹ¼F(xi©żn)ųŪ─▄Öz╦„║═ų¬ūRĮM┐Ś����Ż¼╠ßĖ▀Öz╦„ĮY╣¹Ą─┐╔ė├ąį��ĪŻ
ĪĪĪ���ĪŻ©Č■Ż®Ę©┬╔ą┼ŽóšZ┴xÖz╦„─Żą═ę└ō■(j©┤)ī”Ū░╩÷Ę©┬╔ų¬ūR¾wŽĄĄ─Ęų╬÷┼c╠Įėæ���Ż¼▒Š╬─╠ß│÷┴╦ę╗éĆė├ė┌ŠW(w©Żng)ĮjŁh(hu©ón)Š│Ž┬Ę©┬╔ą┼ŽóšZ┴xÖz╦„Ą──ŻöMĮŌøQĘĮ░ĖŻ¼▒Ē╩÷╚ńŽ┬Ż║
ĪĪĪ�����ĪŻ©1Ż®ė╔Ę©┬╔ŅIė“īŻ╝ę░┤ššĘ©┬╔ų¬ūR¾wŽĄęÄ(gu©®)ĘČ║═╦ŠĘ©īŹ█`Įø(j©®ng)“×�Ż¼ĮM┐ŚĘ©┬╔ą┼ŽóĖ„ų„Ņ}Ė┼─Ņ║═┼cŲõŽÓī”æ¬Ą─ų¬ūRĪóā╚╚▌����Ż¼░┤šš▒Š¾wĄ─śŗĮ©ĘĮĘ©�Ż¼Į©┴óīė┤╬žSĖ╗����ĪóšZ┴xŪÕ╬·ĪóĻPŽĄ├„┤_Ą─Ę©┬╔ų¬ūR▒Š¾wŻ©ų„Ņ}ĻPŽĄį~▒ĒŻ®�����Ż¼▓ó▒Ż┤µĄĮŽÓĻPĄ─öĄ(sh©┤)ō■(j©┤)Äņųą�ĪŻ
ĪĪĪĪŻ©2Ż®ę└ō■(j©┤)Ę©┬╔ą┼Žóį¬öĄ(sh©┤)ō■(j©┤)╝░Ųõś╦ūRÖCųŲī”ŠW(w©Żng)Ēō╔ŽĘ©┬╔╣½╬─ūįäė▀Mąąś╦ę²║═ĘųŅÉ�Ż¼═©▀^į¬öĄ(sh©┤)ō■(j©┤)Į©┴óĘ©┬╔╣½╬─ų„Ņ}į~┼cĘ©┬╔▒Š¾wŽÓĻPĖ┼─ŅĄ─ė│╔õĻP┬ō(li©ón)����Ż¼īóĻP┬ō(li©ón)Ą─ų„Ņ}į~╝░ī”æ¬Ą─ŠW(w©Żng)ĒōĘ©┬╔╣½╬─ĄžųĘŻ©URLŻ®┤µĘ┼į┌ųĖČ©Ą─öĄ(sh©┤)ō■(j©┤)Äņ▒Ēųą�����ĪŻ
ĪĪĪ�ĪŻ©3Ż®Ė∙ō■(j©┤)ė├æ¶▌ö╚ļĄ─▓ķįāšłŪ¾ĻPµIį~����Ż¼į┌ęčįOėŗĄ─Ī░Ę©┬╔ą┼Žóų„Ņ}ĻPŽĄį~▒ĒĪ▒▓ķįā─Ż░Õųą▀MąąŽÓĻPĖ┼─Ņ║═╔ŽĪóŽ┬╬╗Ė┼─ŅĄ─Öz╦„�����Ż¼šę│÷┼cų«ŽÓĻP┬ō(li©ón)║═Ųź┼õĄ─ų„Ņ}į~╗“╔Ž╬╗����ĪóŽ┬╬╗į~ĪŻ
ĪĪĪ����ĪŻ©4Ż®░┤ššį¬öĄ(sh©┤)ō■(j©┤)╦∙ś╦ę²Ą─ų„Ņ}į~Ą─ŠW(w©Żng)ĒōĘ©┬╔╣½╬─ĄžųĘŻ©URLŻ®Öz╦„│÷ŠW(w©Żng)Ēōųąė├æ¶╦∙ąĶꬥ─Ę©┬╔╣½╬─ā╚╚▌ęį╝░ŽÓĻPĄ─Ę©┬╔��ĪóĘ©ęÄ(gu©®)Īó┼ą└²ų¬ūR��ĪŻ
ĪĪĪĪŽ┬├µĮo│÷ę╗éĆ╗ź┬ō(li©ón)ŠW(w©Żng)Łh(hu©ón)Š│Ž┬īŹ¼F(xi©żn)╔Ž╩÷蹊┐╗∙▒Š╦╝┬Ę║═ĘĮ░ĖČ°čąųŲĄ─Ę©┬╔ą┼ŽóšZ┴xÖz╦„įŁą═Ż║
ĪĪĪĪ«öė├æ¶į┌▌ö╚ļ?y©▓n)^(q©▒)ė“▌ö╚ļ─│éĆ┤²▓ķĘ©┬╔ą┼Žó╠žš„į~║¾���Ż¼ŽĄĮy(t©»ng)╩ūŽ╚░┤šš─Ż║²▓ķįāĄ─ĘĮ╩Įį┌ų„Ņ}į~▒ĒÄņųą▀MąąÆ▀├Ķ�����Ż¼«öšęĄĮ┼cė├æ¶▌ö╚ļĄ─╠žš„į~ŽÓę╗ų┬Ą─ų„Ņ}į~Ģr�Ż¼Ė∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)ÄņĖ„▒ĒĄ─ųĖßś�Ż¼ļSų«┤_Č©┴╦įōį~į┌ĻPŽĄ▒ĒųąĄ─╬╗ų├╝░Ųõ╔ŽĪóŽ┬╬╗ĻP┬ō(li©ón)į~║═╦∙ī┘ĘČ«Ā�����Ż╗Įø(j©®ng)╦„ę²┐ņ╦┘šęĄĮęčįOų├į¬öĄ(sh©┤)ō■(j©┤)ś╦ūR║═Č©╬╗Ą─Web Ēō├µųą┼cė├æ¶▓ķįā╠žš„į~ŽÓŲź┼õĄ─Ę©┬╔ą┼Žó����Ż¼▀MČ°▀Ć┐╔ęį═┌Š“│÷┼cų«ŽÓĻPĄ─Ųõ╦¹ą┼ŽóĪŻ└²╚ń���Ż¼«ö╬ęéāąĶę¬▓ķšęėąĻPĪ░ōp║”┘rāöĪ▒ĘĮ├µĄ─┼ą└²ĢrŻ¼╩ūŽ╚▀xō±Ī░Ę©┬╔┼ą└²Ī▒▀xĒŚ��Ż¼╚╗║¾į┌Ī░ĻPµIį~Ī▒┐“ųą▌ö╚ļĪ░ōp║”┘rāöĪ▒��Ż¼ätÄņųą╦∙ėą║¼Ī░ōp║”┘rāöĪ▒ę╗į~Ą─┼ą└²ś╦Ņ}Š∙Ģ■│÷¼F(xi©żn)į┌Ų┴─╗╔ŽŻ╗į┌Ųõųą▀xō±─│ĒŚŻ¼╝┤┐╔▌ö│÷įō┼ą└²Ą─ā╚╚▌�����Ż¼═¼ĢrīóŽÓĻPą┼Žó╚ń╦∙ėą║¼ėą═¼ę╗Ę©į║╗“Ę©╣┘īÅ┼ąĄ─ŅÉ╦Ų░Ė└²��Ż¼┼c┤╦┼ą└²ŽÓĻPĄ─Ę©┬╔����ĪóĘ©ęÄ(gu©®)�����Ż¼įŁ���Īó▒╗Ėµ╦∙╔µ╝░╦∙ėą┼ą└²Ą╚Š∙▒╗Öz╦„│÷üĒŻ©ęŖłD2Ż®���ĪŻ
ĪĪĪĪłD2 šZ┴xÖz╦„įŁą═╩Š└²
╬Õ����ĪóĮY šZ
▒Š╬─═©▀^ī”«öŪ░ć°ā╚═ŌĻPė┌ą┼ŽóÖz╦„ĘĮĘ©Ą─蹊┐Ęų╬÷��Ż¼ĮY║Ž╦ŠĘ©īŹ█`ųąĘ©┬╔ą┼ŽóÖz╦„å¢Ņ}�Ż¼╠ß│÷┴╦ęį╦ŠĘ©╩┬īŹ×ķų„ŠĆ����Īóę└ō■(j©┤)Ę©┬╔ą┼ŽóĄ─ų¬ūRå╬į¬╝░ŲõšZ┴x╠žš„īŹ¼F(xi©żn)ŠW(w©Żng)ĮjųąĘ©┬╔ą┼Žóų¬ūR│ķ╚Ī║═šZ┴xÖz╦„Ą─įOėŗśŗ╝▄║═ĮŌøQĘĮ░ĖŻ¼▓óĮ©┴ó┴╦ę╗éĆÖz╦„įŁą═ŽĄĮy(t©»ng)ī”Ųõ▀Mąą┴╦─ŻöMīŹ¼F(xi©żn)ĪŻ’@╚╗����Ż¼ęį▀@ĘNĘĮ╩Į╠ß╣®Ą─Öz╦„ĮY╣¹▓╗į┘ŠųŽ▐ė┌ęįŪ░Ą─ĻPµIūųŲź┼õÖz╦„����Ż¼╦³│õĘųĄž└¹ė├┴╦Ę©┬╔ą┼ŽóķgĄ─šZ┴xĻPŽĄ�����Ż¼▓╗āH▒ŻšŽ┴╦ė├æ¶▓ķįāąĶŪ¾┼c─┐ś╦ĮY╣¹Ą─ę╗ų┬ąįŻ¼═¼Ģr▀Ć─▄ē“═┌Š“│÷┼cė├æ¶ąĶŪ¾ŽÓĻP┬ō(li©ón)Ą─īŹė├ą┼Žó�Ż¼▀MČ°╠ßĖ▀┴╦ŠW(w©Żng)ĒōųąĘ©┬╔ą┼ŽóĄ─▓ķ╚½┬╩║═▓ķ£╩┬╩�����Ż¼×ķ╗ź┬ō(li©ón)ŠW(w©Żng)Łh(hu©ón)Š│Ž┬Ę©┬╔ų¬ūRĄ─½@╚Ī╠ß╣®┴╦┐╔ĮĶĶbĄ─└Ēšō║═īŹ█`ę└ō■(j©┤)�ĪŻ